有一个数据文件,在每行结尾都有\n\n。
http://pan.baidu.com/s/1o6jq5q6
我的系统环境:win7+python3.3+R-3.0.3
在R语言中:
sessionInfo()
[1] LC_COLLATE=Chinese (Simplified)_People's Republic of China.936
[2] LC_CTYPE=Chinese (Simplified)_People's Republic of China.936
[3] LC_MONETARY=Chinese (Simplified)_People's Republic of China.936
[4] LC_NUMERIC=C
[5] LC_TIME=Chinese (Simplified)_People's Republic of China.936
在Python中: chcp 936
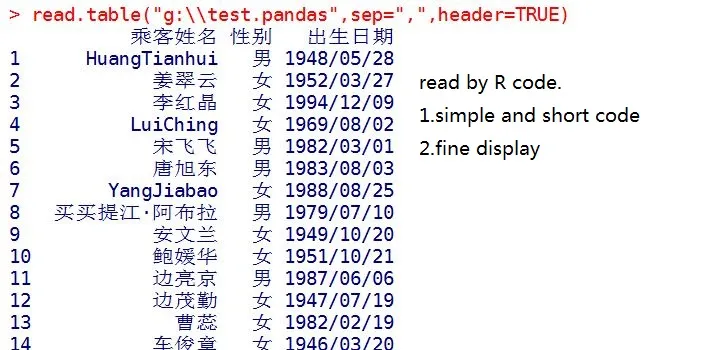
我可以在R中读取它。
read.table("test.pandas",sep=",",header=TRUE)
这很简单。
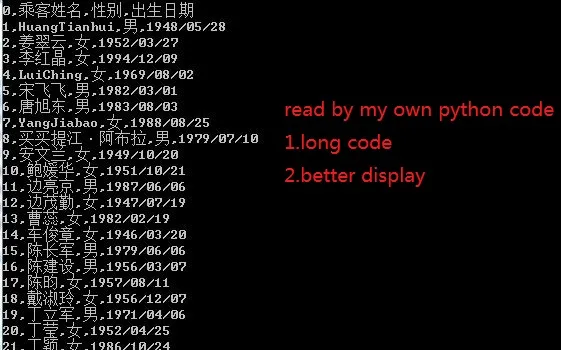
而且我可以在Python中读取它,以获得几乎相同的输出。
fr=open("g:\\test.pandas","r",encoding="gbk").read()
data=[x for x in fr.splitlines() if x.strip() !=""]
for id,char in enumerate(data):
print(str(id)+","+char)
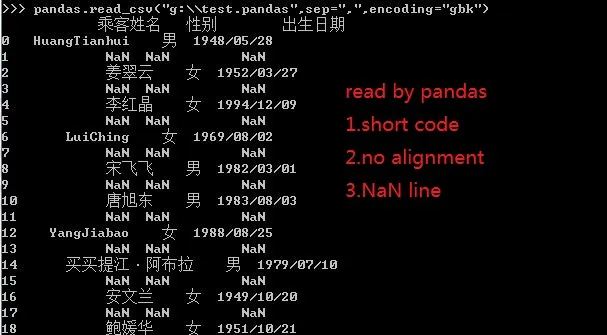
当我在Python模块pandas中阅读时,
import pandas as pd
pd.read_csv("test.pandas",sep=",",encoding="gbk")
我在输出中发现了两个问题:
1)如何进行正确对齐(我已在其他帖子中提出此问题)
如何在Python中使用非ANSI字符设置pandas中的对齐
2)每个实际数据中都有一个NaN行。
我能否改进我的pandas代码以在控制台中获得更好的显示?