我正在阅读有关BFS和DFS的图形算法。当我分析通过DFS在图形中查找强连通分量的算法时,我产生了疑问。为了查找强连通分量,书籍《算法导论》首先对图形运行DFS以获取顶点的完成时间,然后再根据第一次DFS得到的完成时间的递减顺序在图的转置上运行第二次DFS。但我不明白为什么第二个DFS必须按照完成时间顺序运行。
我的意思是,即使我们直接在转置的图上运行DFS(忽略完成时间),它是否也可以给我们提供连接组件,因为通过转置,我们已经阻止了通往其他组件的路径。
编辑-以下是斯坦福大学深度讲解该主题的一些好视频:
http://openclassroom.stanford.edu/MainFolder/CoursePage.php?course=IntroToAlgorithms(请参阅6.有向图中的连通性)
我的解释:
如果您不按第一次dfs完成时间的降序运行第二个dfs,则可能会错误地将整个图形视为单个强连通分量(SCC)。
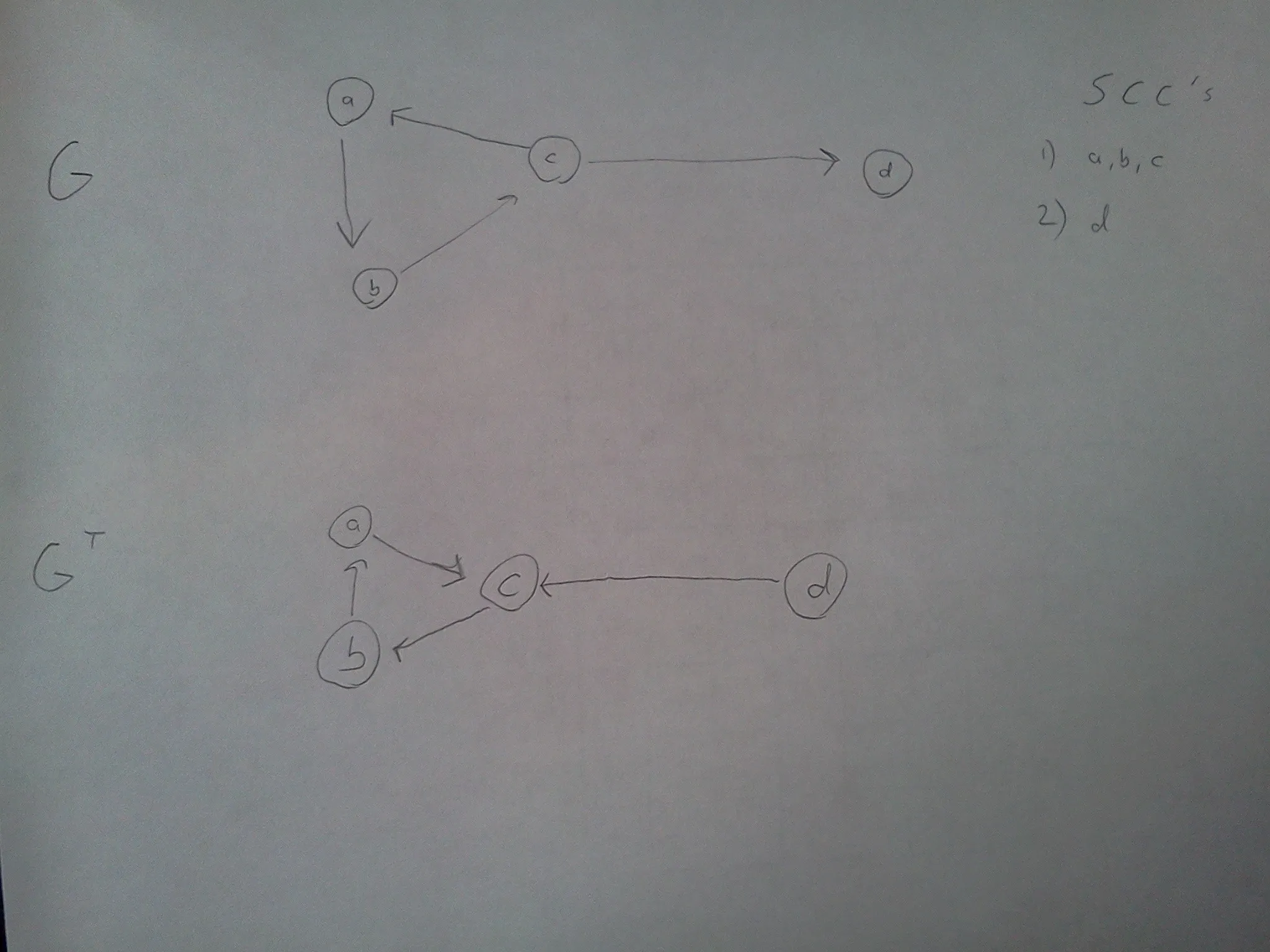
请注意,在我的示例中,节点 始终具有第一次dfs中最低的完成时间。 a 、 b 或 c 中的一个将具有最高的完成时间。假设a具有最高的完成时间,因此如果我们按照降序完成时间运行第二个dfs,则a将首先被遍历。
现在,如果您从G 的转置中的节点d 开始运行第二个dfs,您将得到包含整个图形的深度优先森林,并因此得出结论整个图形是SCC,这显然是错误的。然而,如果您从a开始dfs,则不仅会发现a 、b和c 作为SCC,更重要的是它们将被标记为已访问,即通过涂色为灰色或黑色,当您继续对d进行dfs时,您不会遍历其SCC,因为您会意识到其相邻节点已被访问。
如果您查看Cormen的DFS代码,则会发现:
DFS(G)
1 for each vertex u in G.V
2 u.color = WHITE
3 u.π = NIL
4 time = 0
5 for each vertex u in G.V
6 if u.color == WHITE
7 DFS-VISIT(G, u)
DFS-VISIT(G, u)
1 time = time + 1 // white vertex u has just been discovered
2 u.d = time
3 u.color = GRAY
4 for each v in G.adj[u]
5 if v.color == WHITE
6 v.π = u
7 DFS-VISIT(G, u)
8 u.color = BLACK // blacken u; it is finished
9 time = time + 1
10 u.f = time
如果您没有使用递减完成时间,那么DFS的第6行只会被执行一次,因为DFS-VISIT将会递归地访问整个图。这样产生的是一个深度优先森林中的单一树,并且每棵树都是一个强连通分量。单一树的原因在于,一棵树是由其根节点有空前驱的方式来确定的。