我正在尝试自学图论,并且现在正在尝试理解如何在图中找到强连通分量。我已经阅读了 SO 上的几个不同的问题/答案(例如,1,2,3,4,5,6,7,8),但我找不到一个具有完整逐步示例的答案可以供我参考。
根据CORMEN(算法导论),一种方法是:
观察以下图形(问题3.4来自这里。我已经在这里和这里找到了几个解决方案,但我正在尝试分解并自己理解它。)
- 调用DFS(G)计算每个顶点u的完成时间f[u]
- 计算G的转置
- 调用DFS(Transpose(G)),但在DFS的主循环中,按照f[u]递减的顺序考虑顶点
- 将步骤3的深度优先森林中每棵树的顶点作为单独的强连通分量输出
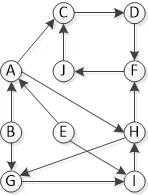
运行以A为起点的DFS:
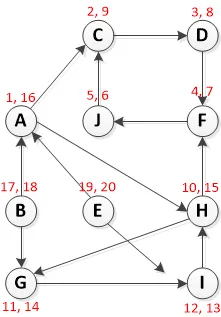
请注意以 [Pre-Visit,Post-Visit] 格式呈现的红色文本。
步骤2:计算 G 的转置
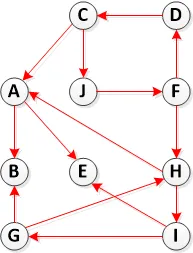
第三步:调用DFS(Transpose(G)),但在DFS的主循环中,按照f[u](如步骤1中计算的)递减的顺序考虑顶点
好的,按照后序遍历(完成时间)值递减的顺序考虑顶点:
{E, B, A, H, G, I , C, D, F ,J}
因此,在这一步中,我们在G^T上运行DFS,但从以上列表中的每个顶点开始:
- DFS(E):{E}
- DFS(B):{B}
- DFS(A):{A}
- DFS(H):{H, I, G}
- DFS(G):从列表中删除,因为它已经被访问过了
- DFS(I):从列表中删除,因为它已经被访问过了
- DFS(C):{C, J, F, D}
- DFS(J):从列表中删除,因为它已经被访问过了
- DFS(F):从列表中删除,因为它已经被访问过了
- DFS(D):从列表中删除,因为它已经被访问过了
第四步:将第三步深度优先森林中每个树的顶点作为一个单独的强连通分量输出。
所以我们有五个强连通分量:{E},{B},{A},{H,I,G},{C,J,F,D}
B和E:它们的入度都为零,并且自己形成了一个(退化的)强连通分量。我认为链接的答案是错误的。(比我快了40秒。) - greybeard