维基百科说,三路合并比两路合并更少出错,并且通常不需要用户干预。为什么会这样呢?
提供一个三路合并成功而两路合并失败的例子会很有帮助。
提供一个三路合并成功而两路合并失败的例子会很有帮助。
这张幻灯片 来自Perforce的一个演示,内容很有趣:
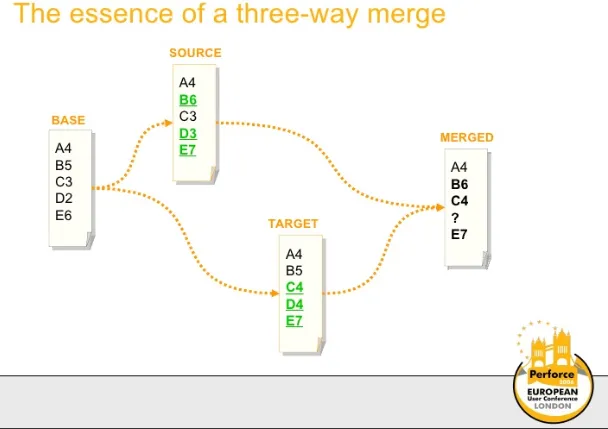
三方合并工具的基本逻辑很简单:
- 比较基准文件、源文件和目标文件
- 识别源文件和目标文件中的“块”:
- 与基准不匹配的块
- 与基准匹配的块
- 然后,组合合并结果,包括:
- 在所有3个文件中都匹配的块
- 在源文件或目标文件中与基准不匹配但不是同时不匹配的块
- 与基准不匹配但相互匹配的块(即,在源文件和目标文件中以相同方式更改)
- 冲突块的占位符,由用户解决。
请注意,这张插图中的“块”是纯粹象征性的。每个“块”都可以代表文件中的行、层次结构中的节点,甚至是目录中的文件。这完全取决于特定合并工具的功能。
您可能会问3向合并相对于2向合并有什么优势。实际上,不存在所谓的2向合并,只有能够比较两个文件并允许您通过选择一个文件中的块或另一个文件中的块来“合并”的工具。
只有3向合并才能让您知道一个块是否对源文件作出了更改以及更改是否冲突。
三路合并是指两个变更集在应用时被合并,而不是先应用一个变更集,然后将结果与另一个变更集合并。
例如,在同一个位置添加了一行的两个更改可能被解释为两个添加,而不是一行的更改。
例如,文件a已被两个人修改,一个人添加了moose,另一个人添加了mouse。
#File a
dog
cat
#diff b, a
dog
+++ mouse
cat
#diff c, a
dog
+++ moose
cat
现在,如果我们在应用更改集时合并它们,我们将得到(三方合并)
#diff b and c, a
dog
+++ mouse
+++ moose
cat
但是,如果我们应用 b ,然后查看从 b 到 c 的更改,它看起来就像我们只是将一个“u”更改为一个“o”(两路合并)。
#diff b, c
dog
--- mouse
+++ moose
cat
