我试图使用正则表达式将DataFrame系列分割成多个列。
可复现的代码:
pd.DataFrame({"Animals":["(Cat1, Dog1)", "(Cat1, Dog2)", "(Cat1, Dog3)", "(Cat2, Dog1)", "(Cat2, Dog2)", "(Cat2, Dog3)"]})
输入表格:

期望表格:
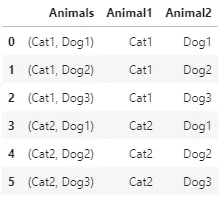
提前感谢!
编辑:
根据评论,Shubham的解决方案最为简洁:
df[['Animals1', 'Animals2']] = df['Animals'].str.extract(r'(\w+), (\w+)')
您也可以使用 replace 方法来去除括号和空格,并使用 split(',') 方法,同时设置参数 expand=True 来创建新的列:
df[['Animal1', 'Animal2']] = (df['Animals'].replace(['\(', '\)', '\s+'], '', regex=True)
.str.split(',', expand=True))
df
Out[1]:
Animals Animal1 Animal2
0 (Cat1, Dog1) Cat1 Dog1
1 (Cat1, Dog2) Cat1 Dog2
2 (Cat1, Dog3) Cat1 Dog3
3 (Cat2, Dog1) Cat2 Dog1
4 (Cat2, Dog2) Cat2 Dog2
5 (Cat2, Dog3) Cat2 Dog3
尝试:
df[['Animal1', 'Animal2']] = df['Animals'].str[1:-1].str.split(', ', expand=True)
Animals Animal1 Animal2
0 (Cat1, Dog1) Cat1 Dog1
1 (Cat1, Dog2) Cat1 Dog2
2 (Cat1, Dog3) Cat1 Dog3
3 (Cat2, Dog1) Cat2 Dog1
4 (Cat2, Dog2) Cat2 Dog2
5 (Cat2, Dog3) Cat2 Dog3
一种方法是:
df = pd.DataFrame({"Animals":["(Cat1, Dog1)", "(Cat1, Dog2)", "(Cat1, Dog3)", "(Cat2, Dog1)", "(Cat2, Dog2)", "(Cat2, Dog3)"]})
df['Animal1'] = df['Animals'].map(lambda x: x.split(', ')[0][1:])
df['Animal2'] = df['Animals'].map(lambda x: x.split(', ')[1][:-1])
extract函数:df[['Animals1', 'Animals2']] = df['Animals'].str.extract(r'(\w+), (\w+)');) - Shubham Sharmaextract()但是分成两行。我猜,指定多个捕获组才使这成为可能。 - David Ericksonstr.extract(),但我实际上从未亲眼见过它被用在你所使用的方式上。 - David Ericksonstr.extract作为另一种解决方案。 - Shubham Sharma