在开始学习Lisp时,我遇到了术语尾递归。它确切指的是什么?
什么是尾递归?
2045
- Ben Lever
7
21也许有点晚,但这是一篇很好的关于尾递归的文章:http://www.programmerinterview.com/index.php/recursion/tail-recursion/ - Sam003
8识别尾递归函数的一个巨大优点是,可以将其转换为迭代形式,从而减轻算法的方法栈开销。建议查看下@Kyle Cronin以及下面其他人的回答。 - KGhatak
1有人能告诉我,归并排序和快速排序是否使用尾递归(TRO)? - majurageerthan
2@majurageerthan - 这取决于特定的算法实现(包括其他任何算法)。 - Bob Jarvis - Слава Україні
https://www.youtube.com/watch?v=-PX0BV9hGZY =) - Abhijit
显示剩余2条评论
29个回答
22
下面是一个快速对比两个函数的代码片段。第一个函数使用传统递归来找到给定数字的阶乘。第二个函数使用尾递归。
非常简单易懂。
判断一个递归函数是否是尾递归,一种简单的方法是看它在基本情况下是否返回具体值,也就是说,不会返回1、true或任何类似的东西,而很可能返回某个方法参数的变体。
另一种方法是观察递归调用是否不涉及加法、算术运算、修改等,也就是说,它只是一个纯粹的递归调用。
public static int factorial(int mynumber) {
if (mynumber == 1) {
return 1;
} else {
return mynumber * factorial(--mynumber);
}
}
public static int tail_factorial(int mynumber, int sofar) {
if (mynumber == 1) {
return sofar;
} else {
return tail_factorial(--mynumber, sofar * mynumber);
}
}
- AbuZubair
1
40!等于1。因此,“mynumber == 1”的意思应该是“mynumber == 0”。 - polerto
15
递归函数是一种调用自身的函数。
它允许程序员使用最少量的代码编写高效的程序。
缺点是如果没有正确编写,它们可能会导致无限循环和其他意外结果。
我将解释简单递归函数和尾递归函数。
为了编写一个简单的递归函数:
- 第一点要考虑的是何时决定退出循环,这就是 if 循环
- 第二个问题是如果我们是自己的函数,则要执行什么过程
从给定的示例中:
public static int fact(int n){
if(n <=1)
return 1;
else
return n * fact(n-1);
}
从上面的例子可以看出
if(n <=1)
return 1;
决定何时退出循环的因素。
else
return n * fact(n-1);
实际处理需要完成什么任务
让我逐一分解任务以便易于理解。
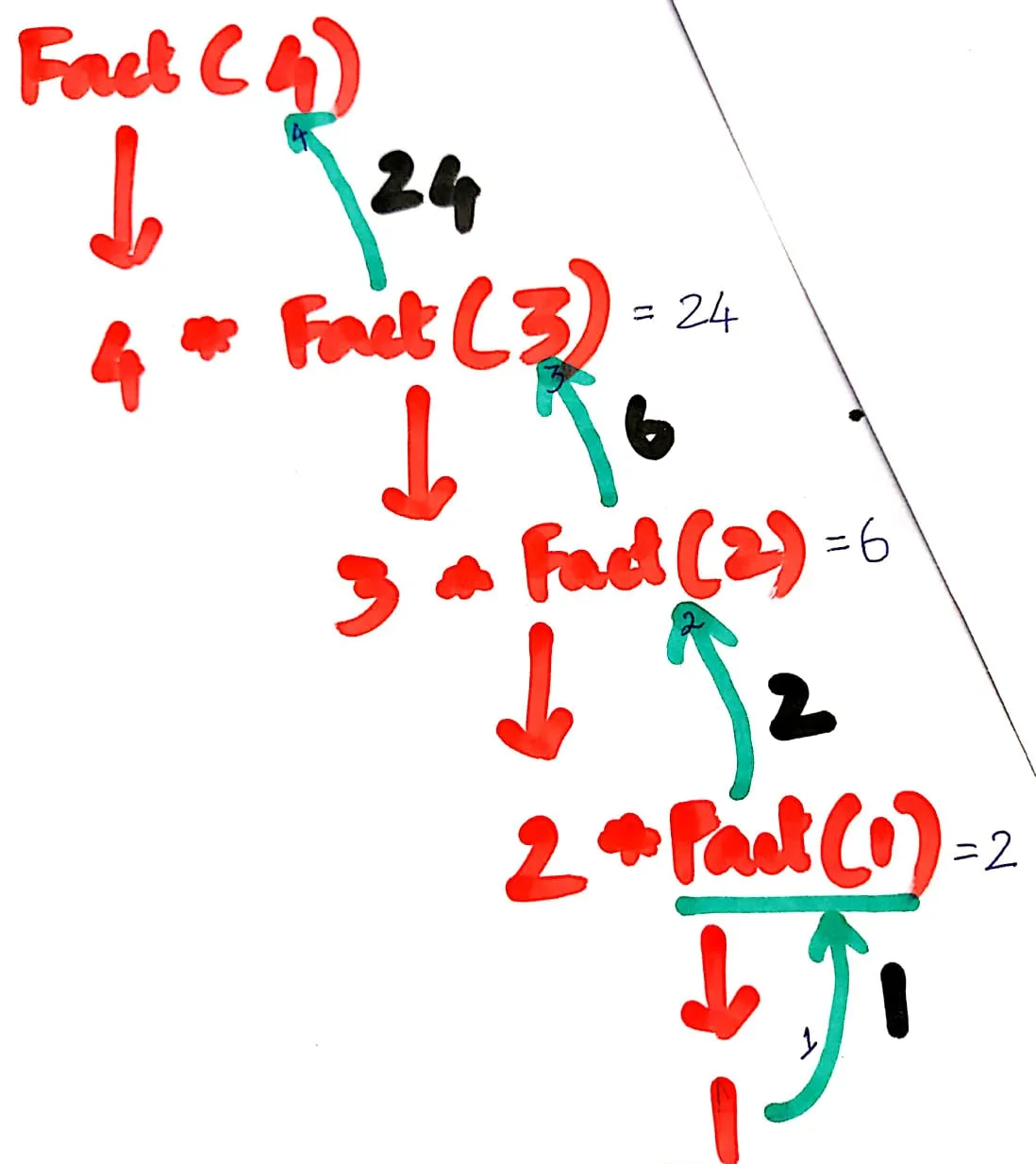
如果我运行fact(4),让我们看看内部会发生什么
- 将n替换为4
public static int fact(4){
if(4 <=1)
return 1;
else
return 4 * fact(4-1);
}
If语句执行失败就进入else循环,因此它返回4 * fact(3)
在堆栈内存中,我们有
4 * fact(3)将n替换为3
public static int fact(3){
if(3 <=1)
return 1;
else
return 3 * fact(3-1);
}
If循环失败,则进入else循环
所以它返回3 * fact(2)
请记住我们调用了```4 * fact(3)``
fact(3)的输出 = 3 * fact(2)
到目前为止,堆栈中有4 * fact(3) = 4 * 3 * fact(2)
在堆栈内存中,我们有
4 * 3 * fact(2)将n=2代入
public static int fact(2){
if(2 <=1)
return 1;
else
return 2 * fact(2-1);
}
If循环失败,则进入else循环
所以返回2 * fact(1)
记得我们调用了4 * 3 * fact(2)
fact(2)的输出为2 * fact(1)
到目前为止,堆栈中有4 * 3 * fact(2) = 4 * 3 * 2 * fact(1)
在栈内存中,我们有
4 * 3 * 2 * fact(1)将 n=1 替换
public static int fact(1){
if(1 <=1)
return 1;
else
return 1 * fact(1-1);
}
If循环为true
所以它返回1
请记住我们调用了4 * 3 * 2 * fact(1)
fact(1) = 1的输出
到目前为止,堆栈中有4 * 3 * 2 * fact(1) = 4 * 3 * 2 * 1
最终,fact(4) = 4 * 3 * 2 * 1 = 24的结果是
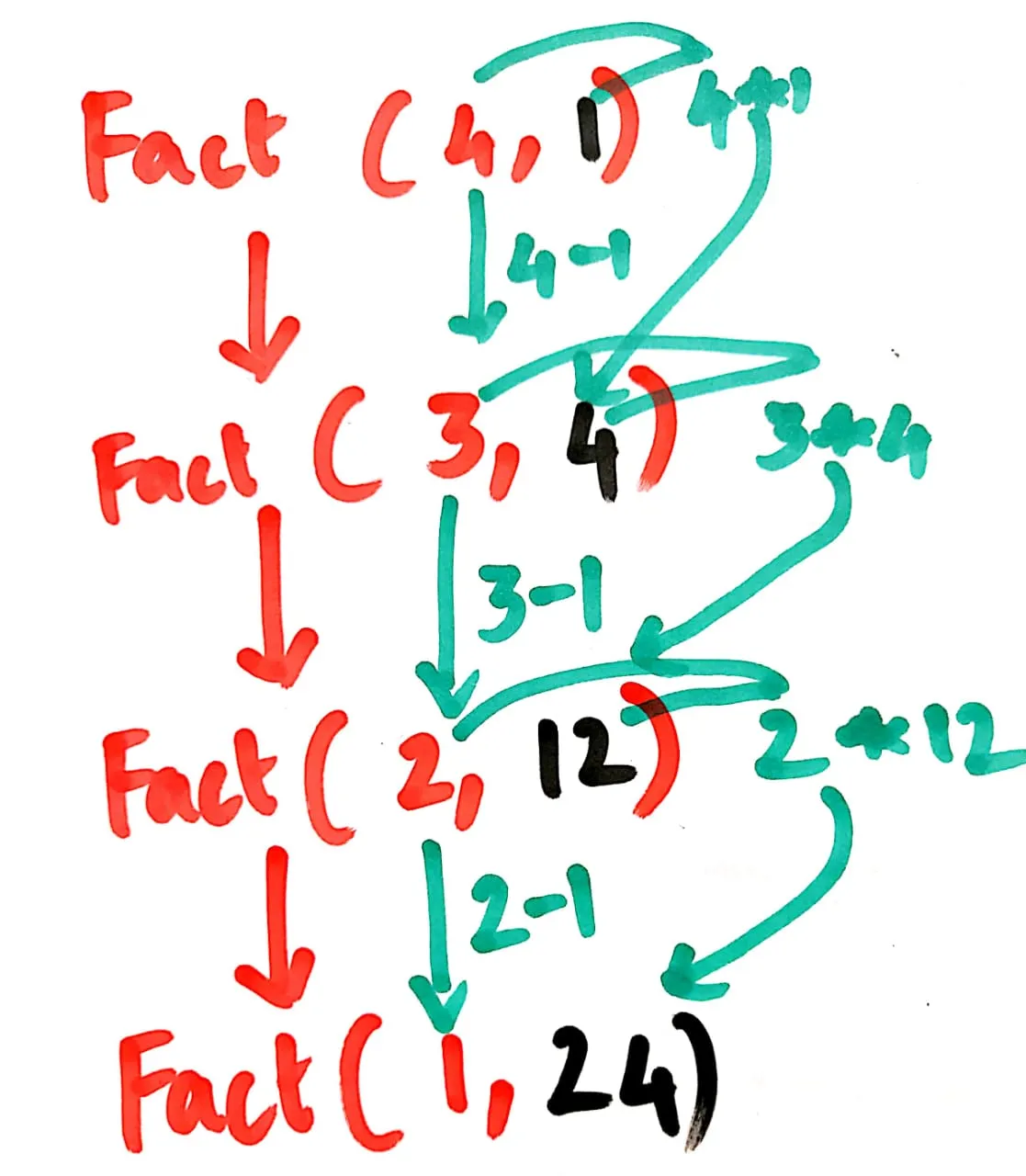
尾递归将是
public static int fact(x, running_total=1) {
if (x==1) {
return running_total;
} else {
return fact(x-1, running_total*x);
}
}
- 将n替换为4
public static int fact(4, running_total=1) {
if (x==1) {
return running_total;
} else {
return fact(4-1, running_total*4);
}
}
If语句失败,因此进入else语句,然后返回fact(3, 4)
在堆栈内存中,我们有
fact(3, 4)替换n=3
public static int fact(3, running_total=4) {
if (x==1) {
return running_total;
} else {
return fact(3-1, 4*3);
}
}
If 循环失败,则进入 else 循环
因此返回 fact(2, 12)
在堆栈内存中,我们有
fact(2, 12)将 n 替换为 2
public static int fact(2, running_total=12) {
if (x==1) {
return running_total;
} else {
return fact(2-1, 12*2);
}
}
public static int fact(1, running_total=24) {
if (x==1) {
return running_total;
} else {
return fact(1-1, 24*1);
}
}
If 循环为真,则返回 running_total
当 running_total = 24 时,输出结果如下
最终,fact(4,1) = 24
- Nursnaaz
1
你可能需要提到你的编程语言是什么。 - wide_eyed_pupil
13
在Java中,这是一个可能的尾递归实现斐波那契函数的代码:
public int tailRecursive(final int n) {
if (n <= 2)
return 1;
return tailRecursiveAux(n, 1, 1);
}
private int tailRecursiveAux(int n, int iter, int acc) {
if (iter == n)
return acc;
return tailRecursiveAux(n, ++iter, acc + iter);
}
与标准递归实现相比,这种方法形成鲜明对比:
public int recursive(final int n) {
if (n <= 2)
return 1;
return recursive(n - 1) + recursive(n - 2);
}
- jorgetown
2
1这个程序对我来说返回了错误的结果,输入8时我得到了36,但应该是21。我有什么遗漏吗?我正在使用Java并复制粘贴它。 - Alberto Zaccagni
1这将返回[1,n]中i的总和。与Fibbonacci无关。对于Fibbo,当
iter <(n-1)时,您需要一个测试来将iter减去acc。 - Askolein13
尾递归函数是一种递归函数,其中在返回之前最后执行的操作是进行递归函数调用。也就是说,递归函数调用的返回值会被立即返回。例如,你的代码应该像这样:
def recursiveFunction(some_params):
# some code here
return recursiveFunction(some_args)
# no code after the return statement
实现尾调用优化或尾调用消除的编译器和解释器可以优化递归代码,以防止堆栈溢出。如果您的编译器或解释器不实现尾调用优化(例如CPython解释器),则以这种方式编写代码没有额外的好处。
例如,这是Python中标准的递归阶乘函数:
def factorial(number):
if number == 1:
# BASE CASE
return 1
else:
# RECURSIVE CASE
# Note that `number *` happens *after* the recursive call.
# This means that this is *not* tail call recursion.
return number * factorial(number - 1)
这是一个尾递归版本的阶乘函数:
def factorial(number, accumulator=1):
if number == 0:
# BASE CASE
return accumulator
else:
# RECURSIVE CASE
# There's no code after the recursive call.
# This is tail call recursion:
return factorial(number - 1, number * accumulator)
print(factorial(5))
你可能需要让你的代码变得更加难以阅读才能利用尾调用优化,就像阶乘示例中所示。(例如,基本情况现在有点不直观,并且“累加器”参数被有效地用作一种全局变量。)
但是,尾调用优化的好处是它可以防止堆栈溢出错误。(我要注意的是,您可以通过使用迭代算法而不是递归算法来获得相同的效果。)
堆栈溢出是由于调用堆栈已经推入了太多帧对象而引起的。当调用函数时,帧对象将被推入调用堆栈中,并在函数返回时从调用堆栈中弹出。帧对象包含诸如局部变量和当函数返回时要返回的代码行等信息。
如果您的递归函数在没有返回的情况下进行了太多递归调用,则调用堆栈可能超过其帧对象限制。 (该数字因平台而异;在Python中,默认情况下为1000个帧对象。)这会导致堆栈溢出错误。(嘿,这就是本网站名称的由来!)
但是,如果你的递归函数最后一件事就是进行递归调用并返回其返回值,则无需将当前帧对象保留在调用堆栈上。毕竟,如果递归函数调用后没有代码,就没有理由保留当前帧对象的局部变量。因此,我们可以立即摆脱当前帧对象,而不是将其保留在调用堆栈中。这样做的最终结果是您的调用堆栈大小不会增加,因此不能堆栈溢出。
编译器或解释器必须具有尾调用优化作为特性,才能识别何时可以应用尾调用优化。即便如此,您可能需要重新排列递归函数中的代码,以利用尾调用优化,并且这种潜在的可读性降低是否值得进行优化取决于您。
- Al Sweigart
3
2尾递归(也称为尾调用优化或尾调用消除)。不;尾调用消除或尾调用优化是可以应用于尾递归函数的东西,但它们并不是同一件事。你可以在Python中编写尾递归函数(如你所示),但它们并不比非尾递归函数更有效,因为Python不执行尾调用优化。 - chepner
1这是否意味着,如果有人成功优化网站并将递归调用变为尾递归,我们就不再会遇到堆栈溢出的问题了?!那太可怕了。 - Nadjib Mami
1这是我唯一理解定义要点的例子。我知道用非尾递归弹出堆栈的内容,但你为我明确了练习。谢谢。 - wide_eyed_pupil
11
这是一个使用尾递归计算阶乘的Common Lisp示例。由于无需使用堆栈,因此可以执行非常大的阶乘计算...
(defun ! (n &optional (product 1))
(if (zerop n) product
(! (1- n) (* product n))))
然后,为了好玩,您可以尝试(format nil "~R" (! 25))
- user922475
10
尾递归是指递归函数在函数结尾处(“尾部”)调用自身,且在递归调用返回后不做任何计算。许多编译器会将递归调用优化为尾递归或迭代调用。
考虑计算一个数的阶乘问题。
一种直接的方法是:
factorial(n):
if n==0 then 1
else n*factorial(n-1)
假设您调用factorial(4)。递归树如下:
factorial(4)
/ \
4 factorial(3)
/ \
3 factorial(2)
/ \
2 factorial(1)
/ \
1 factorial(0)
\
1
在上述情况下,最大递归深度为O(n)。
但是,请考虑以下示例:
factAux(m,n):
if n==0 then m;
else factAux(m*n,n-1);
factTail(n):
return factAux(1,n);
factTail(4)的递归树如下:
factTail(4)
|
factAux(1,4)
|
factAux(4,3)
|
factAux(12,2)
|
factAux(24,1)
|
factAux(24,0)
|
24
同样,在这里,最大递归深度是O(n),但是没有任何调用会向堆栈添加额外的变量。因此编译器可以省略堆栈。
- coding_ninza
9
简而言之,尾递归是指递归调用在函数中作为最后一条语句,以便不必等待递归调用。
因此,这是一个尾递归,即N(x-1, p*x)是函数中的最后一条语句,编译器聪明地发现它可以被优化成一个for循环(阶乘)。第二个参数p携带中间积累的值。
这是上述阶乘函数的非尾递归写法(尽管一些C++编译器可能能够优化它)。
但这并不是:
因此,这是一个尾递归,即N(x-1, p*x)是函数中的最后一条语句,编译器聪明地发现它可以被优化成一个for循环(阶乘)。第二个参数p携带中间积累的值。
function N(x, p) {
return x == 1 ? p : N(x - 1, p * x);
}
这是上述阶乘函数的非尾递归写法(尽管一些C++编译器可能能够优化它)。
function N(x) {
return x == 1 ? 1 : x * N(x - 1);
}
但这并不是:
function F(x) {
if (x == 1) return 0;
if (x == 2) return 1;
return F(x - 1) + F(x - 2);
}
我写了一篇长篇文章,标题为"理解尾递归-Visual Studio C++-汇编视图"

- justyy
3
1你的函数 N 怎么实现尾递归? - Fabian Pijcke
N(x-1) 是函数中的最后一个语句,编译器聪明地发现它可以被优化为一个for循环(阶乘)。 - justyy
我的担忧是,你的函数N与这个主题的被接受答案中的函数recsum完全相同(除了它是一个求和而不是一个乘积),而且recsum被说成是非尾递归的? - Fabian Pijcke
8
尾递归就像你现在所过的生活。因为没有理由或方式返回到“以前”的框架,所以你不断地循环使用同一个堆栈帧。过去已经结束了,可以被丢弃。你只有一个帧,不断向未来移动,直到进程不可避免地停止。
当考虑到一些进程可能利用额外的帧但堆栈不会无限增长时,这个类比就会失效。
当考虑到一些进程可能利用额外的帧但堆栈不会无限增长时,这个类比就会失效。
- Mulan
2
1它不会在“分裂人格障碍”解释下崩溃。 :) 一个“心智的社会”;一个作为社会的心智。 :) - Will Ness
哇!现在这是另一种思考方式。 - sutanu dalui
8
这是 计算机程序的构造和解释 中关于尾递归的摘录。
在对比迭代和递归时,我们必须小心不要混淆递归过程的概念和递归过程的概念。当我们将一个过程描述为递归时,我们指的是过程定义直接或间接地引用了过程本身的语法事实。但是,当我们描述一个遵循某种模式的过程时,比如线性递归,我们说的是这个过程如何演化,而不是过程如何书写的语法。我们可能会感到不安,因为我们将递归过程(如fact-iter)称为生成迭代过程。然而,这个过程确实是迭代的:它的状态完全由其三个状态变量捕获,解释器只需跟踪三个变量就能执行该过程。区分过程和过程的区别之一可能令人困惑的原因是,大多数通用语言的实现(包括Ada、Pascal和C)都是设计成这样的,即任何递归过程的解释都会消耗随着过程调用次数增加而增长的内存量,即使所描述的过程原则上是迭代的。因此,这些语言只能通过诸如do、repeat、until、for和while等特殊用途的“循环结构”来描述迭代过程。Scheme的实现不共享这个缺陷,即使递归过程描述的是迭代过程,它也会在恒定空间中执行迭代过程。具有这种属性的实现被称为尾递归。使用尾递归实现,迭代可以使用普通的过程调用机制来表示,因此特殊的迭代结构只有作为语法糖才有用。
在对比迭代和递归时,我们必须小心不要混淆递归过程的概念和递归过程的概念。当我们将一个过程描述为递归时,我们指的是过程定义直接或间接地引用了过程本身的语法事实。但是,当我们描述一个遵循某种模式的过程时,比如线性递归,我们说的是这个过程如何演化,而不是过程如何书写的语法。我们可能会感到不安,因为我们将递归过程(如fact-iter)称为生成迭代过程。然而,这个过程确实是迭代的:它的状态完全由其三个状态变量捕获,解释器只需跟踪三个变量就能执行该过程。区分过程和过程的区别之一可能令人困惑的原因是,大多数通用语言的实现(包括Ada、Pascal和C)都是设计成这样的,即任何递归过程的解释都会消耗随着过程调用次数增加而增长的内存量,即使所描述的过程原则上是迭代的。因此,这些语言只能通过诸如do、repeat、until、for和while等特殊用途的“循环结构”来描述迭代过程。Scheme的实现不共享这个缺陷,即使递归过程描述的是迭代过程,它也会在恒定空间中执行迭代过程。具有这种属性的实现被称为尾递归。使用尾递归实现,迭代可以使用普通的过程调用机制来表示,因此特殊的迭代结构只有作为语法糖才有用。
- ayushgp
1
1我阅读了这里的所有答案,然而这是最清晰的解释,触及了这个概念的真正核心。它用非常直接的方式解释,使一切看起来如此简单明了。请原谅我的粗鲁。它让我感觉其他答案并没有完全抓住重点。我认为这就是SICP的重要性所在。 - englealuze
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 3 尾递归
- 8 这段代码是否是尾递归的?
- 7 以下函数是否是尾递归?
- 3 什么是“有效尾递归”?
- 1084 什么是尾调用优化?
- 14 如何识别什么是尾递归,什么不是尾递归?
- 10 Scala,尾递归与非尾递归,为什么尾递归更慢?
- 4 懒值能否是尾递归的?
- 126 尾递归是如何工作的?
- 38 什么是尾递归消除?