递归函数是一种函数,它
自我调用。它允许程序员使用
最少的代码编写高效的程序。缺点是,如果
编写不当,可能会导致无限循环和其他意外结果。我将解释
简单递归函数和尾递归函数。为了编写
简单递归函数,第一点要考虑的是什么时候决定退出循环,即if循环;第二个要考虑的是,如果我们是自己的函数,应该执行什么过程。从给定的例子中:
public static int fact(int n){
if(n <=1)
return 1;
else
return n * fact(n-1);
}
从上面的例子中
if(n <=1)
return 1;
决定何时退出循环的因素是什么?
else
return n * fact(n-1);
实际处理要做什么?
让我逐一分解任务,以便更容易理解。
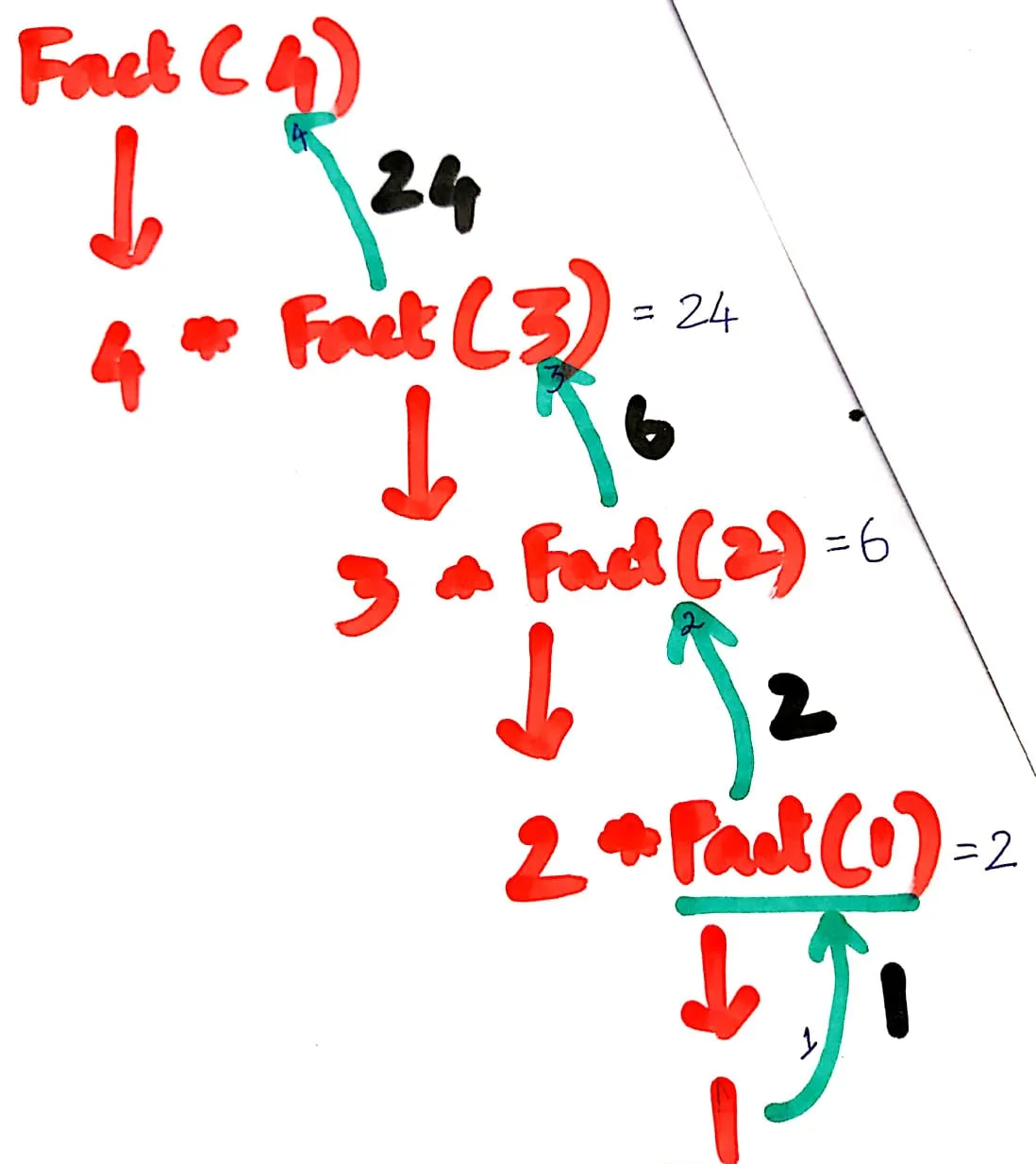
如果我运行
fact(4),让我们看看内部会发生什么。
- 将n替换为4
public static int fact(4){
if(4 <=1)
return 1;
else
return 4 * fact(4-1);
}
如果循环失败,则转到else循环,因此返回
4 * fact(3)
在堆栈内存中,我们有
4 * fact(3)
(将n=3代入)
public static int fact(3){
if(3 <=1)
return 1;
else
return 3 * fact(3-1);
}
如果循环失败,则进入else循环。
因此,它返回`3 * fact(2)`。
请记住我们调用了`4 * fact(3)`。
`fact(3)`的输出为`3 * fact(2)`。
到目前为止,堆栈中有`4 * fact(3) = 4 * 3 * fact(2)`。
在堆栈内存中,我们有`4 * 3 * fact(2)`。
将n替换为2。
public static int fact(2){
if(2 <=1)
return 1;
else
return 2 * fact(2-1);
}
如果循环失败,则进入else循环,所以它返回2 * fact(1)。
记住我们调用了4 * 3 * fact(2)。
fact(2)的输出为2 * fact(1)。
到目前为止,堆栈中有4 * 3 * fact(2) = 4 * 3 * 2 * fact(1)。
在堆栈内存中,我们有4 * 3 * 2 * fact(1)。
将n替换为1。
public static int fact(1){
if(1 <=1)
return 1;
else
return 1 * fact(1-1);
}
如果循环条件为真,则返回1。记住我们调用了4 * 3 * 2 * fact(1)。fact(1)的输出为1。到目前为止,堆栈中有4 * 3 * 2 * fact(1) = 4 * 3 * 2 * 1。最终,fact(4)的结果为4 * 3 * 2 * 1 = 24。
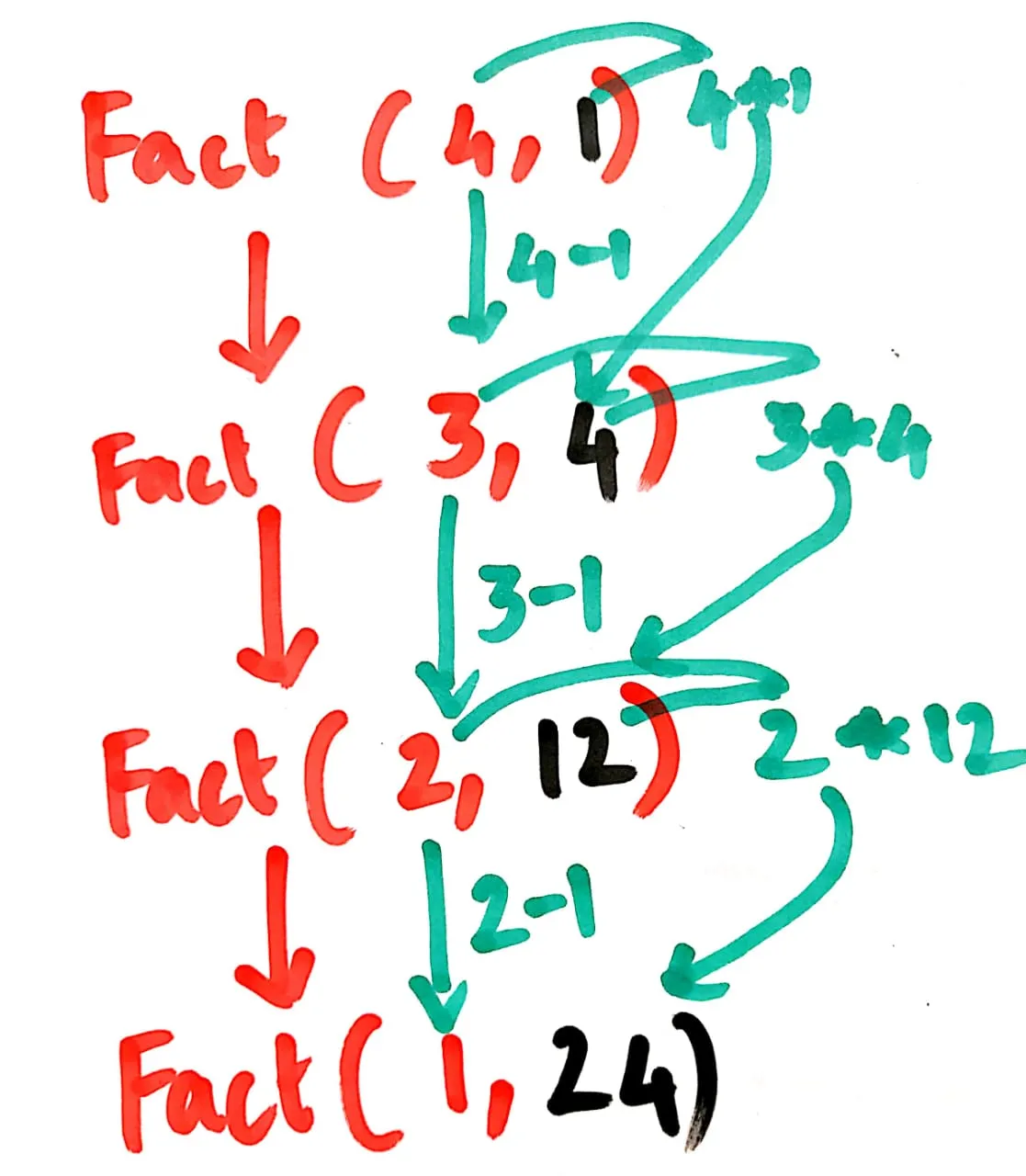
这段文本的意思是:“尾递归将会是”。
public static int fact(x, running_total=1) {
if (x==1) {
return running_total;
} else {
return fact(x-1, running_total*x);
}
}
替换n=4。
public static int fact(4, running_total=1) {
if (x==1) {
return running_total;
} else {
return fact(4-1, running_total*4);
}
}
如果循环失败,就会进入else循环,然后返回fact(3, 4)。
在堆栈内存中,我们有fact(3, 4)。
将n替换为3。
public static int fact(3, running_total=4) {
if (x==1) {
return running_total;
} else {
return fact(3-1, 4*3);
}
}
如果循环失败,则进入else循环。
因此,它返回fact(2,12)。
在堆栈内存中,我们有fact(2,12)。
替换n=2。
public static int fact(2, running_total=12) {
if (x==1) {
return running_total;
} else {
return fact(2-1, 12*2);
}
}
如果循环失败,则进入else循环,因此它返回fact(1,24)。
在堆栈内存中,我们有fact(1, 24)。将n替换为1。
public static int fact(1, running_total=24) {
if (x==1) {
return running_total;
} else {
return fact(1-1, 24*1);
}
}
如果循环为真,则返回running_total。当running_total = 24时,输出结果为24。最终,fact(4,1)的结果为24。
-O3和不使用-O3产生的汇编代码来实现这一点。链接是早期讨论的内容,涵盖了非常相似的领域,并讨论了实现此优化所必需的内容。 - dmckee --- ex-moderator kitten