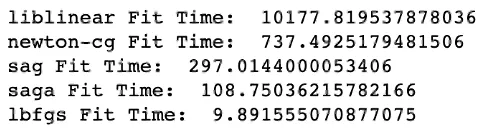
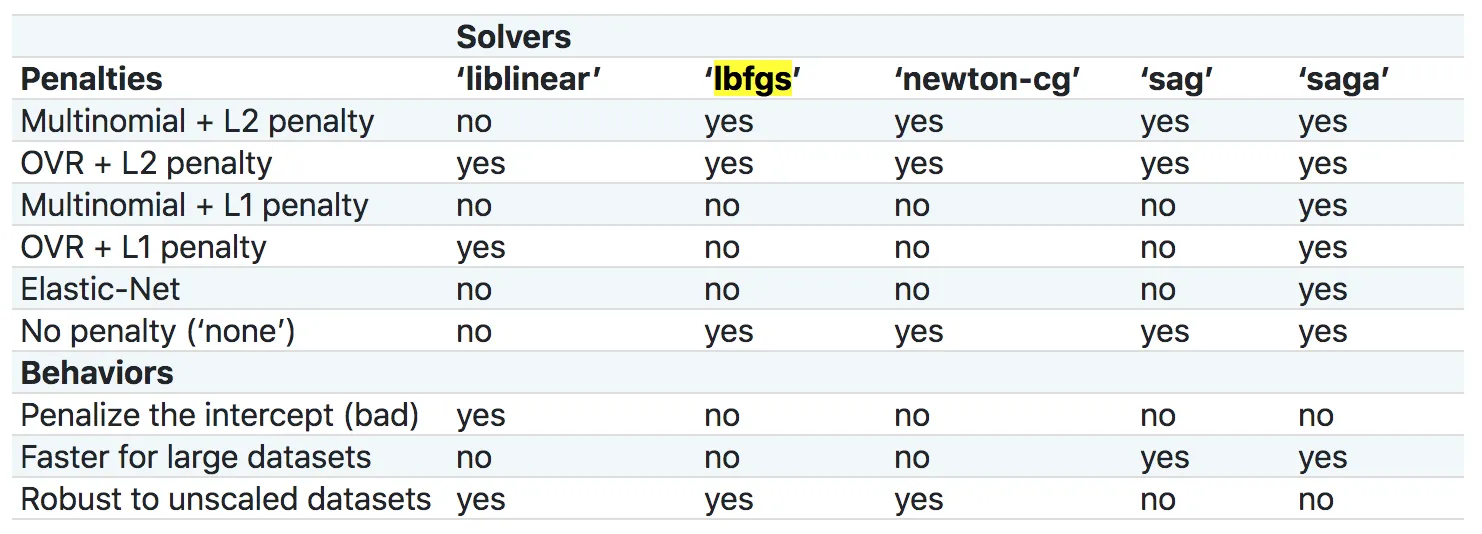
我正在使用sklearn中的LogisticRegression构建一个模型,该模型具有数千个特征和大约60,000个样本。我正在尝试拟合该模型,目前已经运行了约10分钟。我的计算机可用几个内核和千兆字节的RAM,请问是否有任何方法可以加快这个过程。
编辑 这台计算机有24个内核,以下是顶部输出的结果,以提供内存使用情况的想法。
Processes: 94 total, 8 running, 3 stuck, 83 sleeping, 583 threads 20:10:19
Load Avg: 1.49, 1.25, 1.19 CPU usage: 4.34% user, 0.68% sys, 94.96% idle
SharedLibs: 1552K resident, 0B data, 0B linkedit.
MemRegions: 51959 total, 53G resident, 46M private, 676M shared.
PhysMem: 3804M wired, 57G active, 1042M inactive, 62G used, 34G free.
VM: 350G vsize, 1092M framework vsize, 52556024(0) pageins, 85585722(0) pageouts
Networks: packets: 172806918/25G in, 27748484/7668M out.
Disks: 14763149/306G read, 26390627/1017G written.
我正在尝试使用以下内容来训练模型
classifier = LogisticRegression(C=1.0, class_weight = 'auto')
classifier.fit(train, response)
train有大约3000行数据(全是浮点数),而在response中,每行数据只有0或1两个取值。我有大约50000个观测值。