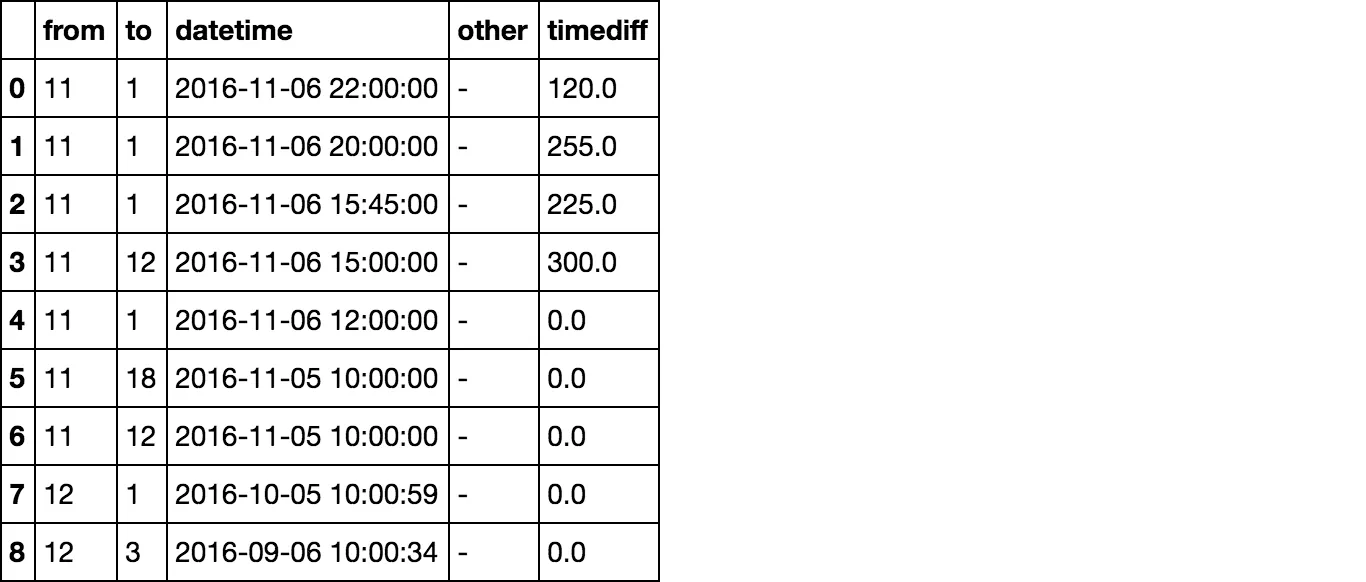
我有一个数据框,看起来像这样:
from to datetime other
-------------------------------------------------
11 1 2016-11-06 22:00:00 -
11 1 2016-11-06 20:00:00 -
11 1 2016-11-06 15:45:00 -
11 12 2016-11-06 15:00:00 -
11 1 2016-11-06 12:00:00 -
11 18 2016-11-05 10:00:00 -
11 12 2016-11-05 10:00:00 -
12 1 2016-10-05 10:00:59 -
12 3 2016-09-06 10:00:34 -
我想要按照"from"和"to"列来进行分组,然后按照"datetime"列进行降序排序,并最后计算这些被分组的对象中当前时间与下一个时间之间的时间差。例如,在这种情况下,我希望有一个如下所示的数据框:
from to timediff in minutes others
11 1 120
11 1 255
11 1 225
11 1 0 (preferrably subtract this date from the epoch)
11 12 300
11 12 0
11 18 0
12 1 25
12 3 0
我无法理解如何解决这个问题!!是否有出路?非常感谢任何帮助!!非常感谢!