我正在尝试理解和实现Keras回归模型的GridSearch方法。这是我的一个简单可复现的回归应用。
import pandas as pd
import numpy as np
import sklearn
from sklearn.model_selection import train_test_split
from sklearn import metrics
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/concrete/slump/slump_test.data")
df.drop(['No','FLOW(cm)','Compressive Strength (28-day)(Mpa)'],1,inplace=True)
# Convert a Pandas dataframe to the x,y inputs that TensorFlow needs
def to_xy(df, target):
result = []
for x in df.columns:
if x != target:
result.append(x)
# find out the type of the target column. Is it really this hard? :(
target_type = df[target].dtypes
target_type = target_type[0] if hasattr(target_type, '__iter__') else target_type
# Encode to int for classification, float otherwise. TensorFlow likes 32 bits.
if target_type in (np.int64, np.int32):
# Classification
dummies = pd.get_dummies(df[target])
return df.as_matrix(result).astype(np.float32), dummies.as_matrix().astype(np.float32)
else:
# Regression
return df.as_matrix(result).astype(np.float32), df.as_matrix([target]).astype(np.float32)
x,y = to_xy(df,'SLUMP(cm)')
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.25, random_state=42)
#Create Model
model = Sequential()
model.add(Dense(128, input_dim=x.shape[1], activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
monitor = EarlyStopping(monitor='val_loss', min_delta=1e-5, patience=5, mode='auto')
checkpointer = ModelCheckpoint(filepath="best_weights.hdf5",save_best_only=True) # save best model
model.fit(x_train,y_train,callbacks=[monitor,checkpointer],verbose=0,epochs=1000)
#model.fit(x_train,y_train,validation_data=(x_test,y_test),callbacks=[monitor,checkpointer],verbose=0,epochs=1000)
pred = model.predict(x_test)
score = np.sqrt(metrics.mean_squared_error(pred,y_test))
print("(RMSE): {}".format(score))
如果您运行这段代码,您可以看到
loss不是很大的数字。
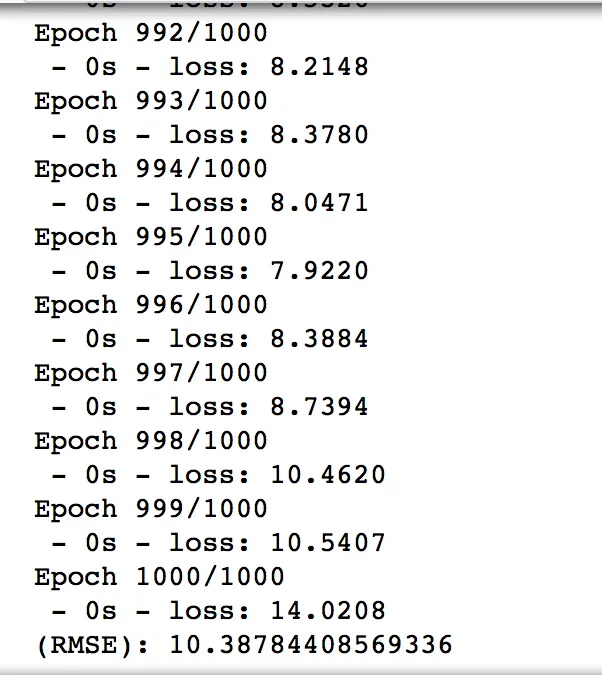 这是我的可生产的GridSearch实现。首先,我简单地搜索了网络并找到了
这是我的可生产的GridSearch实现。首先,我简单地搜索了网络并找到了KerasClassifier的GridSearch应用程序,然后尝试为KerasRegressor进行修改。我不确定我的修改是否正确。如果我假设一般概念是正确的,那么这段代码肯定存在问题,因为损失函数没有意义。损失函数是MSE,但输出是负数,不幸的是我无法找出我的错误所在。from keras.wrappers.scikit_learn import KerasRegressor
import pandas as pd
import numpy as np
import sklearn
from sklearn.model_selection import train_test_split
from sklearn import metrics
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint
from sklearn.model_selection import GridSearchCV
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/concrete/slump/slump_test.data")
df.drop(['No','FLOW(cm)','Compressive Strength (28-day)(Mpa)'],1,inplace=True)
#Convert a Pandas dataframe to the x,y inputs that TensorFlow needs
def to_xy(df, target):
result = []
for x in df.columns:
if x != target:
result.append(x)
# find out the type of the target column. Is it really this hard? :(
target_type = df[target].dtypes
target_type = target_type[0] if hasattr(target_type, '__iter__') else target_type
# Encode to int for classification, float otherwise. TensorFlow likes 32 bits.
if target_type in (np.int64, np.int32):
#Classification
dummies = pd.get_dummies(df[target])
return df.as_matrix(result).astype(np.float32), dummies.as_matrix().astype(np.float32)
else:
#Regression
return df.as_matrix(result).astype(np.float32), df.as_matrix([target]).astype(np.float32)
x,y = to_xy(df,'SLUMP(cm)')
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.25, random_state=42)
def create_model(optimizer='adam'):
# create model
model = Sequential()
model.add(Dense(128, input_dim=x.shape[1], activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer=optimizer,metrics=['mse'])
return model
model = KerasRegressor(build_fn=create_model, epochs=100, batch_size=10, verbose=0)
optimizer = ['SGD', 'RMSprop', 'Adagrad']
param_grid = dict(optimizer=optimizer)
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=1)
grid_result = grid.fit(x_train, y_train)
#summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
