我有一个pdf文件,其中嵌入了一张图片,我该如何使用Python获取该图片的DPI信息。
我尝试使用"pdfimages" popler-util,它给出了图片的像素高度和宽度。
但是我该如何从中获取图片的DPI信息呢?
我有一个pdf文件,其中嵌入了一张图片,我该如何使用Python获取该图片的DPI信息。
我尝试使用"pdfimages" popler-util,它给出了图片的像素高度和宽度。
但是我该如何从中获取图片的DPI信息呢?
与PostScript格式或EPS格式一样,PDF文件没有分辨率,因为它是矢量格式。您能做的就是在pt(或像素)中检索图像尺寸:
from PyPDF2 import PdfFileReader
with io.open(path, mode="rb") as f:
input_pdf = PdfFileReader(f)
media_box = input_pdf.getPage(0).mediaBox
min_pt = media_box.lowerLeft
max_pt = media_box.upperRight
pdf_width = max_pt[0] - min_pt[0]
pdf_height = max_pt[1] - min_pt[1]
 RE。它有红色、蓝色和2个黑色角落,在这里上面的PNG按照96 DPI的标准缩放,下面相同的PNG在PDF中按照每英寸72pt的标准缩放,其中一个黑色角落现在变成了白色(记住它是一个PNG,因此可以有透明颜色,逆转适用)。
RE。它有红色、蓝色和2个黑色角落,在这里上面的PNG按照96 DPI的标准缩放,下面相同的PNG在PDF中按照每英寸72pt的标准缩放,其中一个黑色角落现在变成了白色(记住它是一个PNG,因此可以有透明颜色,逆转适用)。
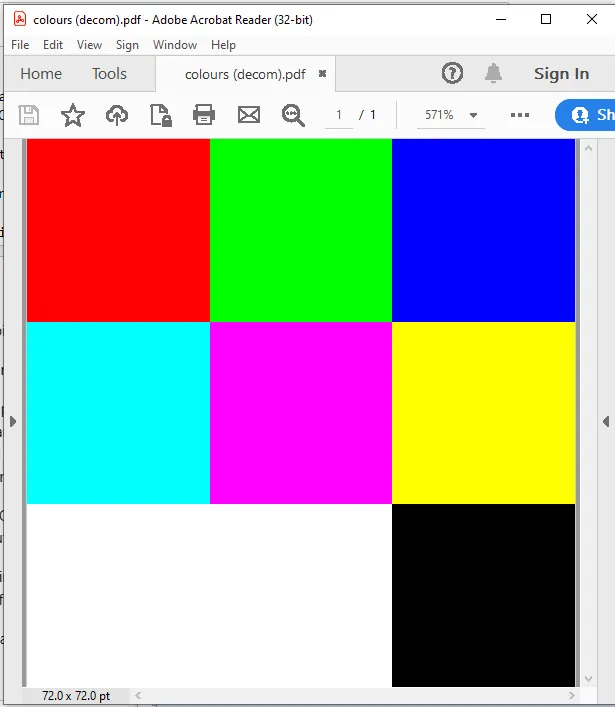
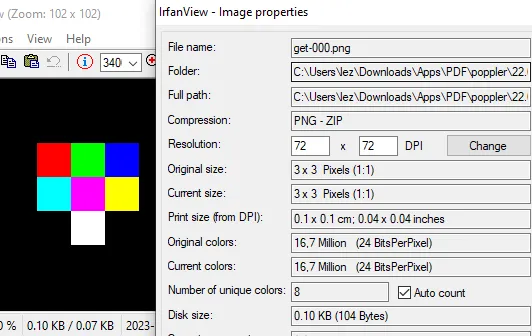
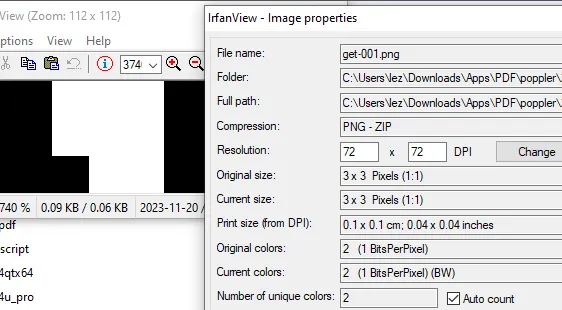
pdfimages -list "colours (decom).pdf
page num type width height color comp bpc enc interp object ID x-ppi y-ppi size ratio
--------------------------------------------------------------------------------------------
1 0 image 3 3 rgb 3 8 image no 6 0 3 3 24B 89%
1 1 smask 3 3 gray 1 1 image no 6 0 3 3 4B 400%
pdfimages也返回图像的dpi:
> pdfimages -list pdf.pdf
page num type width height color comp bpc enc interp object ID x-ppi y-ppi size ratio
--------------------------------------------------------------------------------------------
1 0 image 1308 1675 rgb 3 8 jpeg no 17 0 150 150 166K 2.6%
x-ppi是你所需要的,对于大多数情况来说已经足够了;我还发现这种方法运行非常快
我刚刚写了一些包装器来运行这个shell命令,并使用Python类提取一些信息