我创建了一个流程,基本上循环遍历模型和缩放器,并执行递归特征消除(RFE),如下所示:
我得到了以下错误: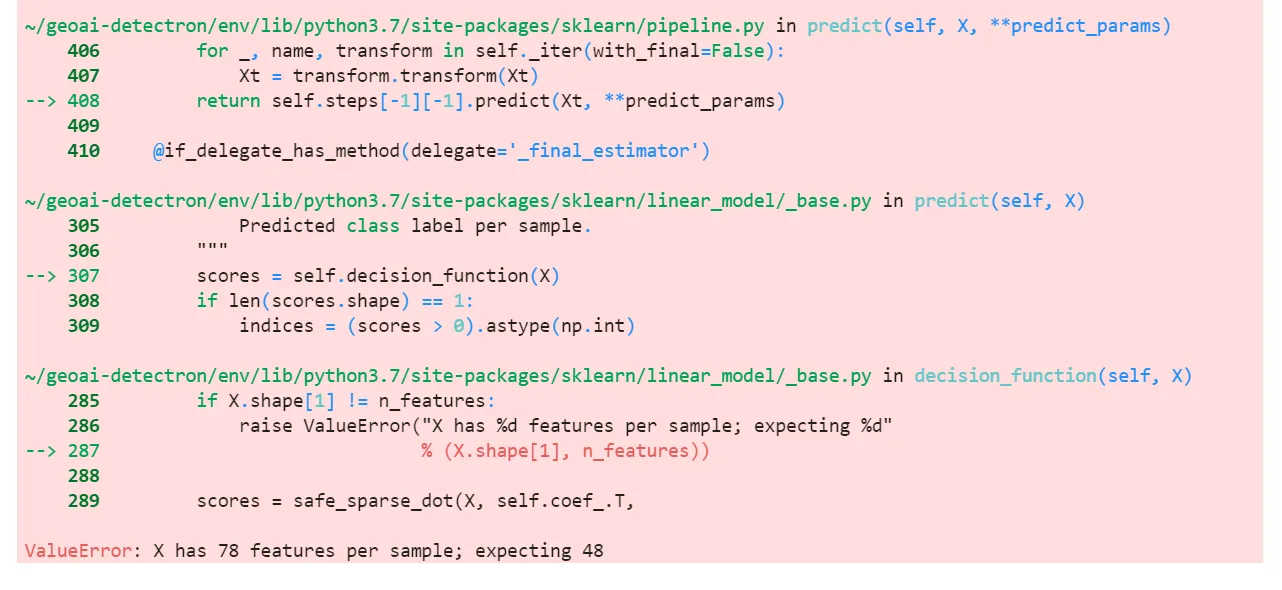 这是
这是
我猜测管道中的
非常感谢任何帮助!
def train_models(models, scalers, X_train, y_train, X_val, y_val):
best_results = {'f1_score': 0}
for model in models:
for scaler in scalers:
for n_features in list(range(
len(X_train.columns),
int(len(X_train.columns)/2),
-10
)):
rfe = RFE(
estimator=model,
n_features_to_select=n_features,
step=10
)
pipe = Pipeline([
('scaler', scaler),
('selector', rfe),
('model', model)
])
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_val)
results = evaluate(y_val, y_pred) #Returns a dictionary of values
results['pipeline'] = pipe
results['y_pred'] = y_pred
if results['f1_score'] > best_results['f1_score']:
best_results = results
print("Best F1: {}".format(best_results['f1_score']))
return best_results
管道在函数内部正常工作,能够正确地预测和评分结果。
然而,当我在函数外部调用 pipeline.predict() 时,例如:
best_result = train_models(models, scalers, X_train, y_train, X_val, y_val)
pipeline = best_result['pipeline']
pipeline.predict(X_val)
我得到了以下错误:
这是pipeline的样子:Pipeline(steps=[('scaler', StandardScaler()),
('selector',
RFE(estimator=LogisticRegression(C=1, max_iter=1000,
penalty='l1',
solver='liblinear'),
n_features_to_select=78, step=10)),
('model',
LogisticRegression(C=1, max_iter=1000, penalty='l1',
solver='liblinear'))])
我猜测管道中的
model期望使用48个特征而不是78个,但是我不明白48这个数字从哪里来,因为在上一个RFE步骤中n_features_to_select设置为78!非常感谢任何帮助!