我正在尝试在ggplot2中使用geom_segment添加手段到geom_density_ridges图中。
library(dplyr)
library(ggplot2)
library(ggridges)
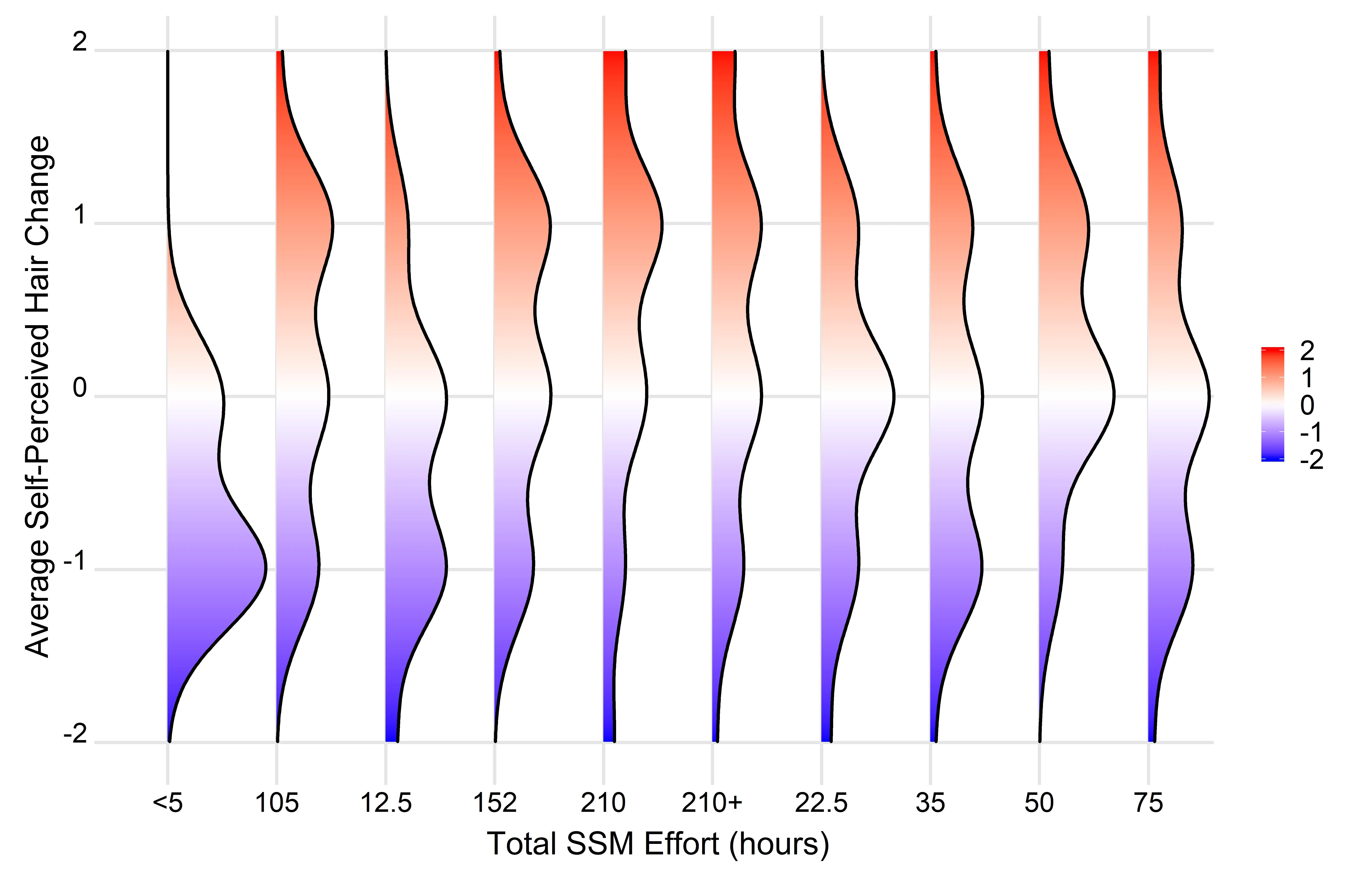
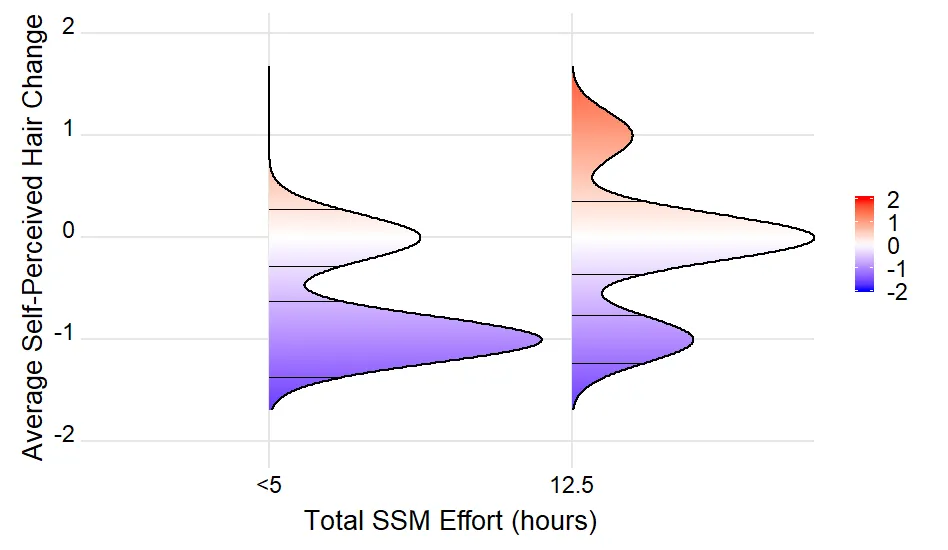
Fig1 <- ggplot(Figure3Data, aes(x = `hairchange`, y = `EffortGroup`)) +
geom_density_ridges_gradient(aes(fill = ..x..), scale = 0.9, size = 1)
ingredients <- ggplot_build(Fig1) %>% purrr::pluck("data", 1)
density_lines <- ingredients %>%
group_by(group) %>% filter(density == mean(density)) %>% ungroup()
p <- ggplot(Figure3Data, aes(x = `hairchange`, y = `EffortGroup`)) +
geom_density_ridges_gradient(aes(fill = ..x..), scale = 0.9, size = 1) +
scale_fill_gradientn( colours = c("#0000FF", "#FFFFFF", "#FF0000"),name =
NULL, limits=c(-2,2))+ coord_flip() +
theme_ridges(font_size = 20, grid=TRUE, line_size=1,
center_axis_labels=TRUE) +
scale_x_continuous(name='Average Self-Perceived Hair Change', limits=c(-2,2))+
ylab('Total SSM Effort (hours)')+
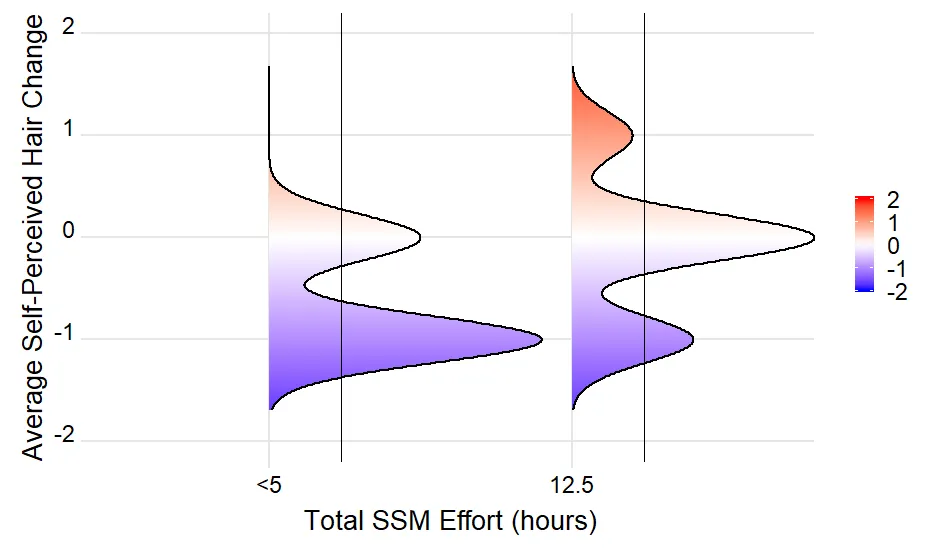
geom_segment(data =density_lines,
aes(x = x, y = ymin, xend = x, yend = ymin+density*scale*iscale))
print(p)
然而,我遇到了以下错误:“错误:data必须具有唯一名称,但存在重复元素”。下面是一个没有数据集均值的图。有什么建议可以修复代码吗?
前35行数据如下:
structure(list(MonthsMassage = c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2,
2, 2, 1, 1), MinutesPerDayMassage = c("0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "11-20 minutes daily",
"11-20 minutes daily", "11-20 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "0-10 minutes daily", "0-10 minutes daily",
"0-10 minutes daily", "11-20 minutes daily", "11-20 minutes daily"
), Minutes = c(5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 15, 15, 15, 5, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 15, 15),
hairchange = c(-1, -1, 0, -1, 0, -1, -1, 0, 0, -1, 0, -1,
-1, 0, 0, -1, 0, -1, 0, -1, -1, -1, -1, -1, 0, -1, -1, -1,
0, 1, -1, 0, 0, -1, 0), HairType1 = c("Templefrontal", "Templefrontal",
"Templefrontal", "Templefrontal", "Templefrontal", "Templefrontal",
"Templefrontal", "other", "Templefrontal", "Templefrontal",
"Templefrontal", "Templefrontal", "Templefrontal", "Templefrontal",
"Templefrontal", "Templefrontal", "Templefrontal", "Templefrontal",
"Templefrontal", "Templefrontal", "Templefrontal", "Templefrontal",
"Templefrontal", "Templefrontal", "Templefrontal", "other",
"other", "other", "Templefrontal", "Templefrontal", "other",
"Templefrontal", "other", "Templefrontal", "Templefrontal"
), HairType2 = c("other", "other", "other", "other", "other",
"other", "other", "other", "other", "Vertexthinning", "Vertexthinning",
"other", "Vertexthinning", "other", "other", "Vertexthinning",
"other", "Vertexthinning", "Vertexthinning", "other", "other",
"other", "Vertexthinning", "other", "Vertexthinning", "other",
"other", "other", "other", "other", "other", "Vertexthinning",
"other", "other", "other"), HairType3 = c("other", "Diffusethinning",
"other", "Diffusethinning", "other", "other", "Diffusethinning",
"Diffusethinning", "Diffusethinning", "other", "Diffusethinning",
"Diffusethinning", "other", "other", "Diffusethinning", "Diffusethinning",
"other", "Diffusethinning", "Diffusethinning", "Diffusethinning",
"other", "other", "other", "other", "other", "other", "other",
"other", "other", "Diffusethinning", "other", "other", "other",
"other", "other"), Effort = c(0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5,
2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 5, 5, 5, 5, 5, 7.5, 7.5), EffortGroup = c("<5",
"<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5",
"<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5", "<5",
"<5", "<5", "<5", "<5", "<5", "<5", "<5", "12.5", "12.5",
"12.5", "12.5", "12.5", "12.5", "12.5")), row.names = c(NA,
-35L), class = c("tbl_df", "tbl", "data.frame"))
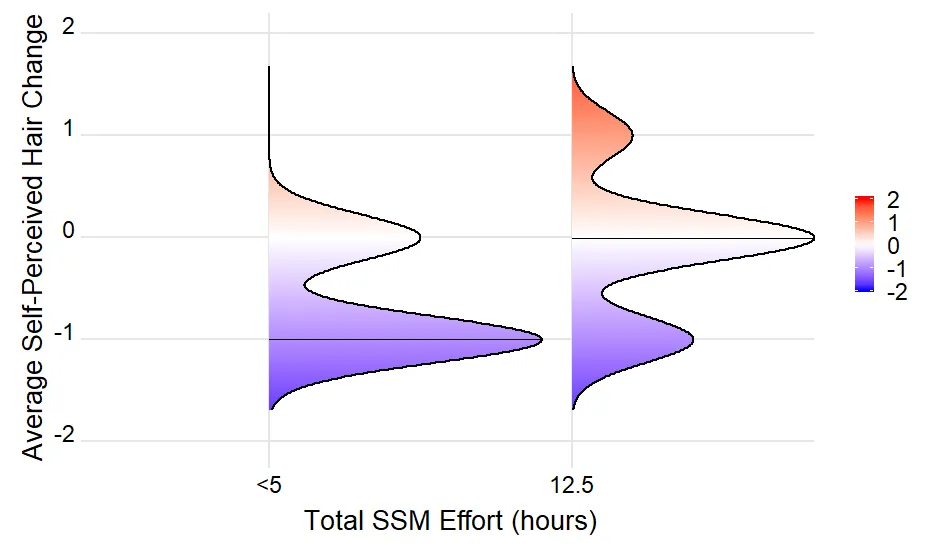
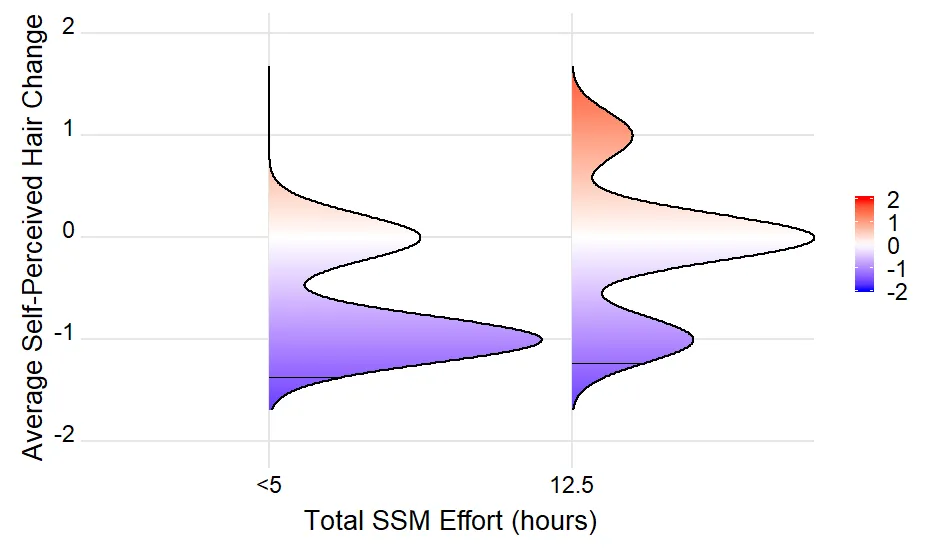
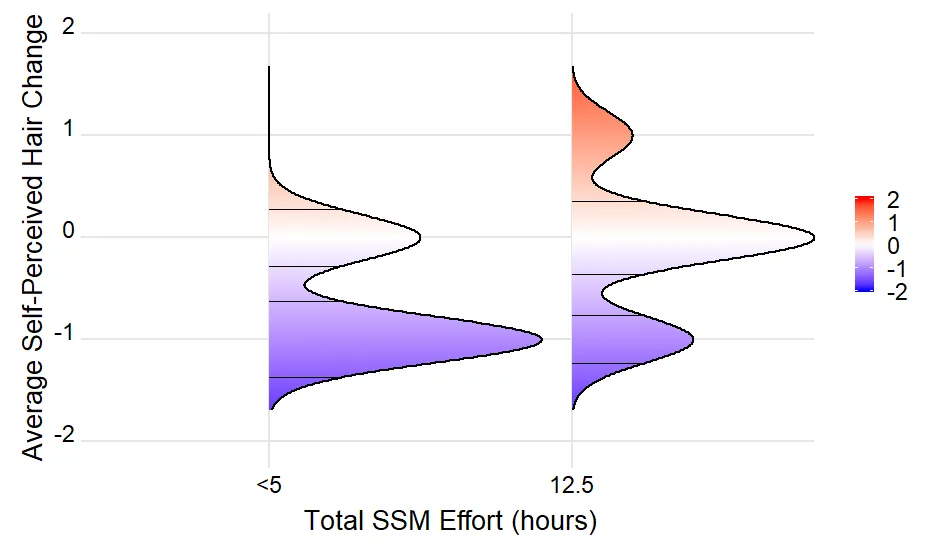
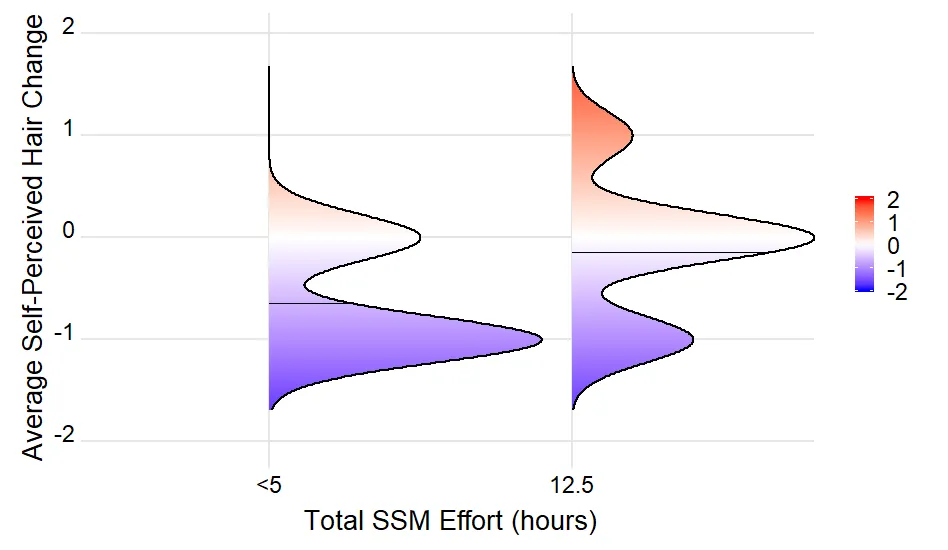
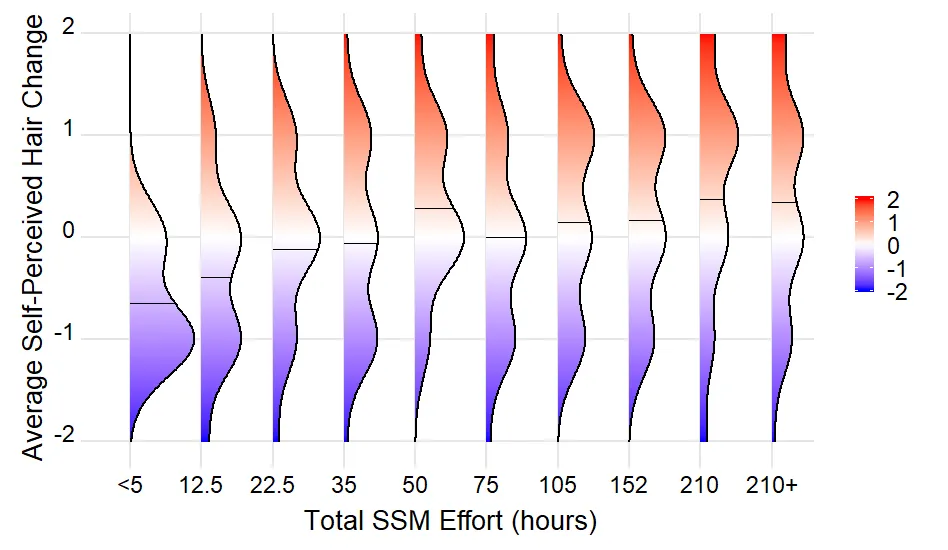
dput(...)的结果(如果这太大,则为dput(head(...)))。我们需要一个可重现的示例来回答您的问题。谢谢。 - Uwestr(density_lines)的结果? - Uwedput()结果。这足以重现问题。density_lines是空的,因为没有记录具有与mean(density)完全相等的density值。使用max(density),为每个山脊线绘制一条水平线。这是你想要的吗?或者,你想要为每个山脊线的峰值(和可能的低谷)绘制一条水平线? - UweEffortGroup被强制转换为因子进行绘图。因子水平按字母顺序排序,这会导致错误的顺序。我建议将EffortGroup转换为因子,并以正确顺序明确指定因子水平。 - Uwe