我想使用python-tesseract来识别类似这样的低分辨率字体:
就价值而言,PIL具有以下内置滤镜:
BLUR、CONTOUR、DETAIL、EDGE_ENHANCE、EDGE_ENHANCE_MORE、EMBOSS、FIND_EDGES、SMOOTH、SMOOTH_MORE和SHARPEN。
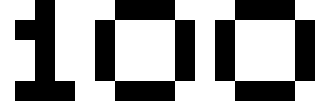
ZIJZHZI
就价值而言,PIL具有以下内置滤镜:
BLUR、CONTOUR、DETAIL、EDGE_ENHANCE、EDGE_ENHANCE_MORE、EMBOSS、FIND_EDGES、SMOOTH、SMOOTH_MORE和SHARPEN。