我已经在词云中绘制了我的文本数据。
这是我拥有的数据框架。
然后我使用这段代码来可视化文本数据:
然后结果就像这样:
你会发现大多数单词重复了2或3次,但它们在词云中的大小并没有显示出来。即使是相同大小的单词,它们的大小也有很大的差异!
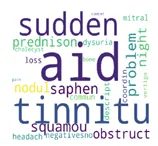
例如:
例如,在此数据框中查看“tinnitu”和“dysuria”,它们的频率都为3,“tinnitu”很大,但“dysuria”很小,很难找到。
谢谢 :)
vocab sumCI
aid 3
tinnitu 3
sudden 3
squamou 3
saphen 3
problem 3
prednison 3
pain 2
dysuria 3
cancer 2
然后我将它转换为字符串,就像这样。(实际上,我已经复制了数据框中每个单词出现的次数,然后将其提供给函数):
aid aid aid tinnitu tinnitu tinnitu sudden sudden sudden squamou squamou squamou
然后我使用这段代码来可视化文本数据:
def generate_wordcloud(text): # optionally add: stopwords=STOPWORDS and change the arg below
wordcloud = WordCloud(
background_color="white",
width=1200, height=1000,
relative_scaling = 1.0,
collocations=False
).generate(text)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
cidf=cidf.loc[cidf.index.repeat(cidf['sumCI'])].reset_index(drop=True)
strCI = ' '.join(cidf['vocab'])
print(strCI)
generate_wordcloud(strCI)
然后结果就像这样:
你会发现大多数单词重复了2或3次,但它们在词云中的大小并没有显示出来。即使是相同大小的单词,它们的大小也有很大的差异!
例如:
例如,在此数据框中查看“tinnitu”和“dysuria”,它们的频率都为3,“tinnitu”很大,但“dysuria”很小,很难找到。
谢谢 :)