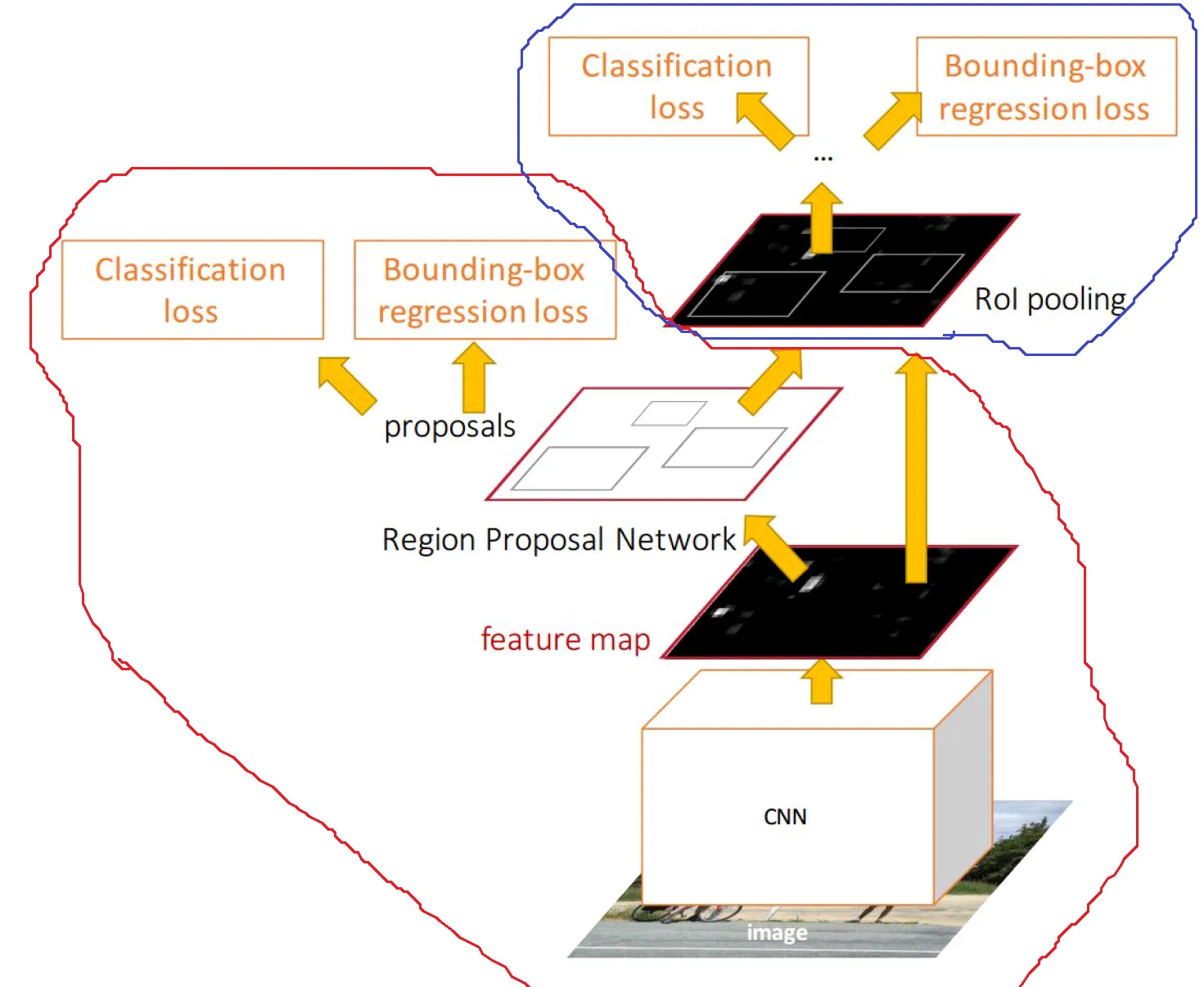
我们知道, faster-RCNN 有两个主要部分:一个是区域提议网络(RPN),另一个是快速RCNN。
我的问题是,既然区域提议网络(RPN)可以输出类别分数和边界框并且可训练,为什么我们还需要Fast-RCNN?
我认为 RPN 对于检测(红色圆圈)已经足够了,而 Fast-RCNN 现在变得多余了(蓝色圆圈)吗?
我的问题是,既然区域提议网络(RPN)可以输出类别分数和边界框并且可训练,为什么我们还需要Fast-RCNN?
我认为 RPN 对于检测(红色圆圈)已经足够了,而 Fast-RCNN 现在变得多余了(蓝色圆圈)吗?