scikit-learn中的向量在Kmeans内部是否被归一化为L2范数单位,还是TfidfVectorizer出了问题?我对文本数据进行聚类,并使用TF-IDF向量化器进行向量化。代码太长无法在此处复制,但基本上我从20个新闻组数据集中向量化和聚类数据。我将向量化器实例化为(未归一化):
VectorizerUn = TfidfVectorizer(min_df=10,
max_df=0.5,
stop_words='english',
decode_error='ignore')
或者(进行L2标准化):
VectorizerL2 = TfidfVectorizer(min_df=10,
max_df=0.5,
stop_words='english',
decode_error='ignore',
norm=u'l2')
我实例化k的意思是使用:
km = KMeans(n_clusters=num_clusters, init='random', n_init=1, verbose=0)
然后我开始将数据进行交叉验证、向量化并拟合训练数据集(下面的向量化器中X代表'Un'或'L2')。
Vectorized = VectorizerX.fit_transform(TrainData.data)
km.fit(Vectorized)
将数据分配给训练集中的消息聚类
new_msg_vec = VectorizerX.transform([new_msg])
predicted_clust = km_clust.predict(new_msg_vec)[0]
new_msg遍历训练数据中的消息。然后,我根据20个新闻组中消息的已知组标签,将聚类分配给组(每个聚类属于其内容大多数的组),并使用测试数据来表征聚类/分类方案的性能。下面是一个没有归一化和使用L2归一化向量化的数据的分类误差与簇数之间的性能图:
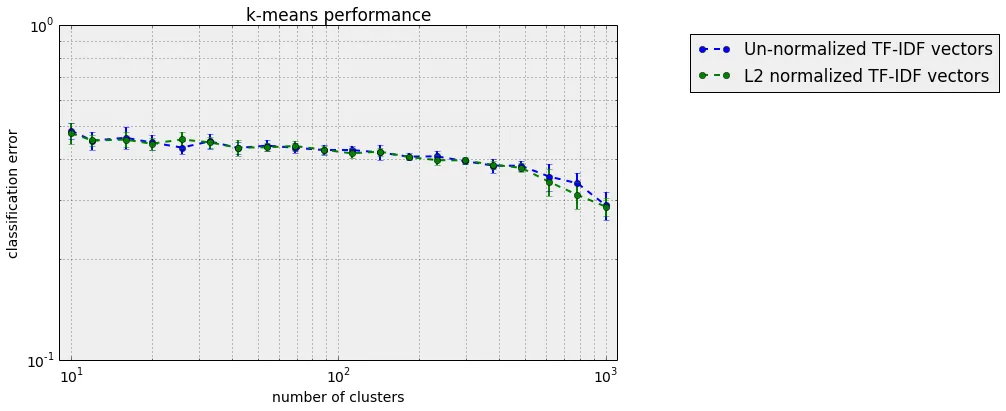
误差条是km.fit(Vectorized)步骤的分类误差的标准偏差经过10次独立运行的结果。这两个结果基本相同。聚类的其他指标(ARI得分、AMI得分、NMI得分)基本上给出了相同的结果。
那么,Kmeans内部是否将向量归一化为L2范数为1,或者TfidfVectorizer的norm参数不起作用?(我正在使用scikit-learn 0.14.1)
编辑:我发现问题可能不在Kmeans上。如果使用L1正则化约束进行向量化(在TfidfVectorizer中设置norm=u'l1'),聚类误差从45%增加到约80%。我更改了标题以反映这一点。
'l2'иҖҢдёҚжҳҜNone(жқҘжәҗ)пјҢеҚіеә”иҜҘдҪҝз”Ёnorm=NoneеҲқе§ӢеҢ–VectorizerUnгҖӮ - YS-L