我知道可以使用其他工具(例如 grep -v)来匹配一个词并反转匹配结果。然而,是否可能使用正则表达式来匹配不包含特定单词(例如 hede)的行?
输入:
hoho
hihi
haha
hede
代码:
grep "<Regex for 'doesn't contain hede'>" input
期望的输出:
hoho
hihi
haha
我知道可以使用其他工具(例如 grep -v)来匹配一个词并反转匹配结果。然而,是否可能使用正则表达式来匹配不包含特定单词(例如 hede)的行?
hoho
hihi
haha
hede
grep "<Regex for 'doesn't contain hede'>" input
hoho
hihi
haha
正则表达式不支持反向匹配的观念并非完全正确。您可以通过使用负面环视来模仿此行为:
^((?!hede).)*$
上述正则表达式将匹配任何不包含字符串'hede'的字符串或不带换行符的行。如前所述,这并不是正则表达式“擅长”的事情(也不应该这样做),但仍然是可能的。
如果您需要匹配换行符,请使用DOT-ALL modifier(以下模式中的尾随s):
/^((?!hede).)*$/s
或者内联使用:
/(?s)^((?!hede).)*$/
(这里的/.../是正则表达式的分隔符,不是模式的一部分)
如果无法使用 DOT-ALL 修饰符,则可以通过字符类 [\s\S] 模拟相同的行为:
/^((?!hede)[\s\S])*$/
一个字符串就是一个由n个字符组成的列表。在每个字符之前和之后都有一个空字符串。因此,一个由n个字符组成的列表将具有n+1个空字符串。考虑字符串"ABhedeCD":
┌──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┐
S = │e1│ A │e2│ B │e3│ h │e4│ e │e5│ d │e6│ e │e7│ C │e8│ D │e9│
└──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┘
index 0 1 2 3 4 5 6 7
其中e是空字符串。正则表达式(?!hede).向前查找,看是否没有子字符串"hede",如果是这种情况(即看到其他东西),那么.(点)将匹配除换行符以外的任何字符。环视也称为零宽断言,因为它们不会消耗任何字符,只是断言/验证某些内容。
所以,在我的例子中,每个空字符串首先被验证,看是否有"hede",然后由.(点)消耗一个字符。正则表达式(?!hede).仅会执行一次,因此它被包装在一个组内,并重复零次或多次:((?!hede).)*。最后,将输入的起始位置和结束位置锚定,以确保整个输入都被消耗:^((?!hede).)*$
正如您所看到的,输入"ABhedeCD"会失败,因为在e3处,正则表达式(?!hede)失败了(有 "hede"在前面)。
grep)都具有使它们在理论上不是正则表达式的功能。 - Bart Kiers^\(\(hede\)\@!.\)*$ - baldrs请注意解决方案非以"hede"开头:
^(?!hede).*$
通常比解决不包含“hede”的方案要高效得多:
^((?!hede).)*$
前者仅检查输入字符串的第一个位置是否为“hede”,而不是每个位置。
^((?!hede).)*$ 在使用 jQuery DataTable 插件时,对于从数据集中排除一个字符串非常有效。 - Alex(.*)(?<!hede)$。@Nyerguds的版本也可以工作,但完全忽视了答案提到的性能问题。 - thisismydesign^((?!hede).)*$?使用 ^(?!.*hede).*$ 不是更高效吗?它可以用更少的步骤完成同样的操作。 - JackPRead如果你只是用它来进行grep操作,你可以使用grep -v hede来获取所有不包含"hede"的行。
根据最新解释,"grep -v"很可能就是你所说的"工具选项"。
grep -v -e hede -e hihi -e ... 进行操作。 - Olaf Dietschegrep -v "hede\|hihi" :)。 - Putnikgrep -vf pattern_file file。 - codeforesteregrep 或 grep -Ev "hede|hihi|etc" 来避免繁琐的转义。 - Amit Naiduegrep 命令示例: egrep -v "hede|hihi|etc" - Roald答案:
^((?!hede).)*$
解释:
^表示字符串的开头,
(分组并捕获到\1(0次或多次(尽可能匹配最多次数)),
(?!向前查看,如果没有,
hede你的字符串,
)查找结束,
.任何字符(除了\n),
)*结束\1(注意:由于您在此捕获上使用了量词,因此仅存储捕获模式的最后一次重复),
$位于可选的\n之前,并且是字符串的结尾
这些给出的答案完全没问题,只是有一个学术上的观点:
在理论计算机科学的意义上,正则表达式不能像这样做。对于它们来说,应该看起来像这样:
^([^h].*$)|(h([^e].*$|$))|(he([^h].*$|$))|(heh([^e].*$|$))|(hehe.+$)
这只进行完全匹配。对于子匹配来说,这样做会更加棘手。
^([^h].*|h([^e].*)?|he([^h].*)?|heh([^e].*)?|hehe.+)$ 或 ^(([^h]|h[^e]|he[^h]|heh[^e]|hehe.).*|h|he|heh)$。 - Bernhard Barker^(?!hede$).*
例如-- 如果你想允许除 "foo" 之外的所有值(即 "foofoo","barfoo" 和 "foobar" 将通过,但 "foo" 将失败),则使用:^(?!foo$).*
当然,如果你正在检查 确切 相等性,在这种情况下更好的一般解决方案是检查字符串相等性,即
myStr !== 'foo'
如果需要使用正则表达式的功能(例如不区分大小写和范围匹配),您甚至可以将否定符号放在测试之外:
!/^[a-f]oo$/i.test(myStr)
这个答案顶部的正则表达式解决方案可能会有所帮助,特别是在需要进行正则表达式测试的情况下(例如通过API)。
" hede "? - eagor\s 指令匹配单个空格字符。 - Roy Tinker^(?!\s*hede\s*$).* - Roy Tinker使用负向先行断言,正则表达式可以匹配不包含特定模式的内容。这一点由Bart Kiers进行了回答和解释,讲得非常好!
但是,在Bart Kiers的答案中,先行断言部分将在匹配任何单个字符的同时测试1至4个字符。我们可以避免这种情况,让先行断言部分检查整个文本,确保不存在'hede',然后正常部分(.*)可以一次性吃掉整个文本。
以下是改进后的正则表达式:
/^(?!.*?hede).*$/
请注意,在负向前瞻部分的(*?)惰性量词是可选的,您也可以使用(*)贪婪量词,具体取决于您的数据:如果'hede'存在并且在文本的前一半,惰性量词可能更快;否则,贪婪量词会更快。但是如果'hede'不存在,则两者都会同样缓慢。
这里是演示代码。
有关前瞻的更多信息,请查看优秀文章:精通前瞻和后顾。
另外,请查看RegexGen.js,这是一个JavaScript正则表达式生成器,可帮助构建复杂的正则表达式。使用RegexGen.js,您可以以更易读的方式构造正则表达式:
var _ = regexGen;
var regex = _(
_.startOfLine(),
_.anything().notContains( // match anything that not contains:
_.anything().lazy(), 'hede' // zero or more chars that followed by 'hede',
// i.e., anything contains 'hede'
),
_.endOfLine()
);
^(?!.*(str1|str2)).*$。 - S.Serpooshan^(?!.*?(?:str1|str2)).*$,具体取决于您的数据。添加 ?: 是因为我们不需要捕获它。 - amobizFWIW,由于正则语言(又称有理语言)在补集下是封闭的,因此总是可以找到一个正则表达式(又称有理表达式)来否定另一个表达式。但不是很多工具实现了这一点。
Vcsn 支持该运算符(它使用后缀标记为 {c})。
首先定义表达式的类型:标签为字母(lal_char),例如选择从a到z的字母(当使用补集时定义字母表是非常重要的),而每个单词计算的“值”仅是一个布尔值:true表示接受该单词,false表示拒绝。
在Python中:
In [5]: import vcsn
c = vcsn.context('lal_char(a-z), b')
c
Out[5]: {a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z} →
接着您需要输入表达式:
In [6]: e = c.expression('(hede){c}'); e
Out[6]: (hede)^c
将此表达式转换为自动机:
In [7]: a = e.automaton(); a
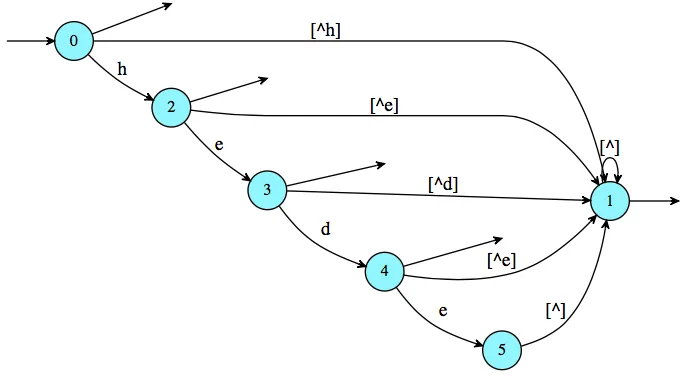
最后,将这个自动机转换为一个简单的表达式。
In [8]: print(a.expression())
\e+h(\e+e(\e+d))+([^h]+h([^e]+e([^d]+d([^e]+e[^]))))[^]*
其中,+ 通常被表示为 |,\e 表示空字,而 [^] 通常被写成 .(任何字符)。因此,稍微改写一下,可以得到正则表达式:()|h(ed?)?|([^h]|h([^e]|e([^d]|d([^e]|e.)))).*。
()|h(ed?)?|([^h]|h([^e]|e([^d]|d([^e]|e.)))).* 在使用 egrep 时对我无效。它匹配了 hede。我还尝试将其锚定到开头和结尾,但仍然无效。 - Pedro Gimeno|之间的优先级将不会很好地配合。'^(()|h(ed?)?|([^h]|h([^e]|e([^d]|d([^e]|e.)))).*)$'。 - akimhehe 是拒绝的意思。我已经更正了文本,但忘记更正快照。 - akim这里有一个很好的解释,说明为什么否定任意正则表达式并不容易。但是,我必须同意其他答案:如果这不是一个假设性的问题,那么在这里使用正则表达式并不是正确的选择。
我决定评估一些已经呈现的选项并比较它们的性能,以及使用一些新功能。 在.NET正则表达式引擎上进行基准测试:http://regexhero.net/tester/
前7行不应匹配,因为它们包含搜索表达式,而下面7行应该匹配!
Regex Hero is a real-time online Silverlight Regular Expression Tester.
XRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex HeroRegex HeroRegex HeroRegex HeroRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her Regex Her Regex Her Regex Her Regex Her Regex Her Regex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her is a real-time online Silverlight Regular Expression Tester.Regex Hero
egex Hero egex Hero egex Hero egex Hero egex Hero egex Hero Regex Hero is a real-time online Silverlight Regular Expression Tester.
RRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her
egex Hero
egex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her is a real-time online Silverlight Regular Expression Tester.
Regex Her Regex Her Regex Her Regex Her Regex Her Regex Her is a real-time online Silverlight Regular Expression Tester.
Nobody is a real-time online Silverlight Regular Expression Tester.
Regex Her o egex Hero Regex Hero Reg ex Hero is a real-time online Silverlight Regular Expression Tester.
结果以每秒迭代次数为单位,作为3次运行的中位数 - 数字越大越好
01: ^((?!Regex Hero).)*$ 3.914 // Accepted Answer
02: ^(?:(?!Regex Hero).)*$ 5.034 // With Non-Capturing group
03: ^(?!.*?Regex Hero).* 7.356 // Lookahead at the beginning, if not found match everything
04: ^(?>[^R]+|R(?!egex Hero))*$ 6.137 // Lookahead only on the right first letter
05: ^(?>(?:.*?Regex Hero)?)^.*$ 7.426 // Match the word and check if you're still at linestart
06: ^(?(?=.*?Regex Hero)(?#fail)|.*)$ 7.371 // Logic Branch: Find Regex Hero? match nothing, else anything
P1: ^(?(?=.*?Regex Hero)(*FAIL)|(*ACCEPT)) ????? // Logic Branch in Perl - Quick FAIL
P2: .*?Regex Hero(*COMMIT)(*FAIL)|(*ACCEPT) ????? // Direct COMMIT & FAIL in Perl
因为 .NET 不支持动作动词 (*FAIL 等),所以我无法测试 P1 和 P2 的解决方案。
总体上,最易读且在性能方面最快的解决方案似乎是使用简单负向先行断言的 03。这也是 JavaScript 最快的解决方案,因为 JS 不支持其他解决方案中更高级的正则表达式特性。
^(?!.*hede)。/// 另外,最好将匹配语料库和不匹配语料库的表达式分别排名,因为通常情况下大多数行是匹配或者不匹配的。 - ikegami
([^h]*(h([^e]|$)|he([^d]|$)|hed([^e]|$)))*有什么问题吗?它的思想很简单。继续匹配直到看到不想要的字符串的开头,然后只在字符串未完成的N-1种情况下进行匹配(其中N为字符串的长度)。这N-1种情况是“h之后非e”,“he之后非d”和“hed之后非e”。如果你成功通过了这些N-1种情况,那么你就成功地没有匹配上不想要的字符串,所以你可以开始再次寻找[^h]*。 - stevendesu^([^h]*(h([^e]|$)|he([^d]|$)|hed([^e]|$))?)*$这个模式在 "hhede" 等包含部分"hede"的实例之前出现时失败了。 - jaytea