我正在尝试使用Python 3.6.5下的Seaborn 0.9.0绘制一些简单数据。这些数据只有两个点,但它们有不同的分类。分类本身只是
生成的图表显示:
为什么图例中会有额外的“类型”
1或2。但是当我使用Seaborn绘图时,图例显示了三种类型:0,1和2。import numpy
import seaborn
import pandas
from matplotlib import pyplot
X = numpy.array([
[-1, -1, 1],
[1, 1, 2]
])
data = pandas.DataFrame(X, columns=('x','y','type'))
seaborn.scatterplot(data=data, x='x', y='y', hue='type')
pyplot.show()
生成的图表显示:
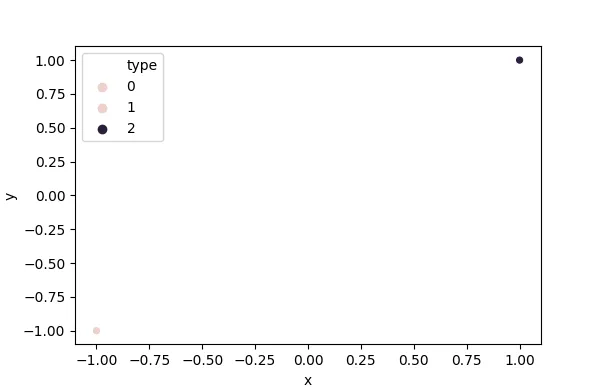
x=X[:,0], y=X[:,1], hue=X[:,2],但结果相同。Seaborn文档对于hue参数的说明如下:
但他们没有澄清“分类”是什么意思,行为如何以及有何不同。我还阅读了分类数据绘图教程,但没有找到答案。在数据中使用像可以是分类数据或数值型数据,尽管在后一种情况下,颜色映射的行为会有所不同。
'1'和'2'这样的字符串只会导致错误:AttributeError: 'str' object has no attribute 'view'
为什么图例中会有额外的“类型”
0?并且,之后如何使用更有意义的类别标签?
在阅读分类数据绘图教程时,我发现了这个:
如果您的数据具有Pandas Categorical数据类型,则可以在那里设置类别的默认顺序。如果传递给分类轴的变量看起来是数字,则级别将被排序。但即使使用数字标记它们,数据仍然被视为分类数据,并在分类轴上的序数位置(特别是在0、1、...处)绘制:
这部分解释了正在发生的事情的一部分(并没有解释为什么会有额外的0类别),但即使使用Pandas分类类型也无济于事。添加
data['type'] = data['type'].astype('category')
...将这些数据转换为分类类型,但Seaborn仍然会报错:
TypeError: data type not understood


