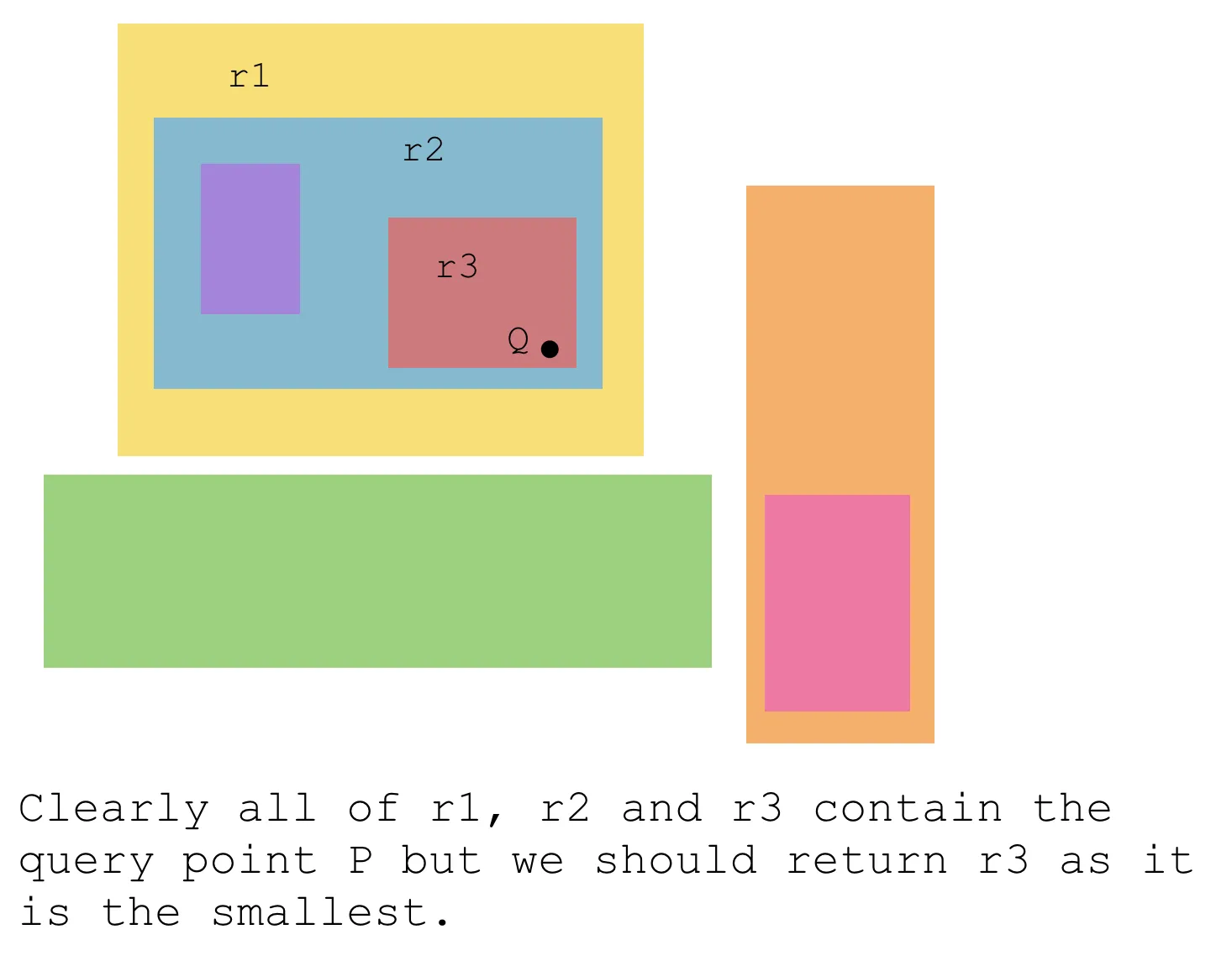
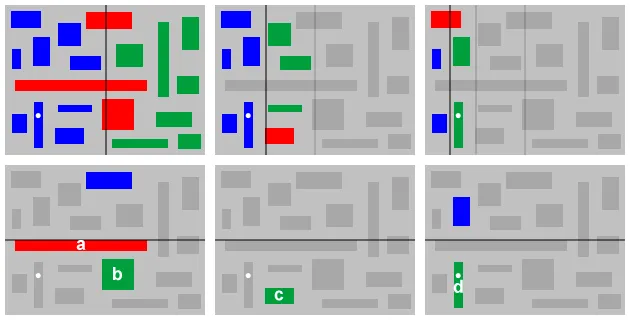
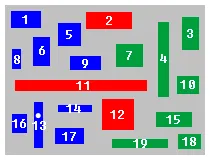
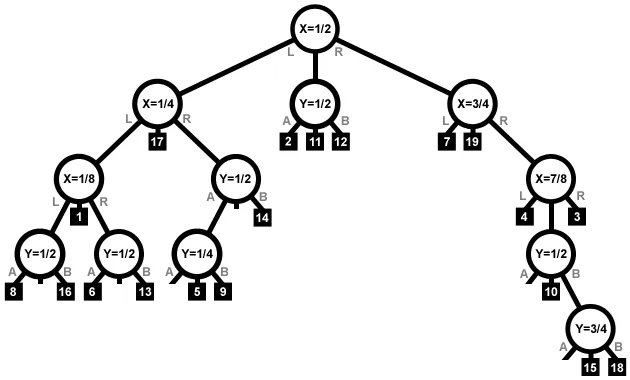
您可以沿着矩形的边界将区域从 xMin 到 xMax 和 yMin 到 yMax 进行分区。这最多可得到 (2n - 1)^2 个字段。每个字段要么完全为空,要么被可见(部分)单个矩形占据。现在,您可以轻松地创建一个带有指向顶部矩形的链接的树结构(例如,在x和y方向上计算划分的数量,在中间进行更多的划分并创建一个节点...进行递归)。因此查找将需要 O(log n^2),即次线性。数据结构需要 O(n^2) 的空间。
以下是更好的复杂度实现,因为索引的搜索可以分开,而搜索顶部矩形只需要 O(log n),不管矩形的配置如何,且相当简单易实现:。
private int[] x, y;
private Rectangle[][] r;
public RectangleFinder(Rectangle[] rectangles) {
Set<Integer> xPartition = new HashSet<>(), yPartition = new HashSet<>();
for (int i = 0; i < rectangles.length; i++) {
xPartition.add(rectangles[i].getX());
yPartition.add(rectangles[i].getY());
xPartition.add(rectangles[i].getX() + rectangles[i].getWidth());
yPartition.add(rectangles[i].getY() + rectangles[i].getHeight());
}
x = new int[xPartition.size()];
y = new int[yPartition.size()];
r = new Rectangle[x.length][y.length];
int c = 0;
for (Iterator<Integer> itr = xPartition.iterator(); itr.hasNext();)
x[c++] = itr.next();
c = 0;
for (Iterator<Integer> itr = yPartition.iterator(); itr.hasNext();)
y[c++] = itr.next();
Arrays.sort(x);
Arrays.sort(y);
for (int i = 0; i < x.length; i++)
for (int j = 0; j < y.length; j++)
r[i][j] = rectangleOnTop(x[i], y[j]);
}
public Rectangle find(int x, int y) {
return r[getIndex(x, this.x, 0, this.x.length)][getIndex(y, this.y, 0, this.y.length)];
}
private int getIndex(int n, int[] arr, int start, int len) {
if (len <= 1)
return start;
int mid = start + len / 2;
if (n < arr[mid])
return getIndex(n, arr, start, len / 2);
else
return getIndex(n, arr, mid, len - len / 2);
}