目前我每次运行脚本时都需要将一个相当大的CSV导入为数据帧。有没有一种好的解决方案,可以在运行之间保持该数据帧的可用性,以便我不必花费所有时间等待脚本运行?
14个回答
667
最简单的方法是使用pickle并使用to_pickle函数:
df.to_pickle(file_name) # where to save it, usually as a .pkl
然后,您可以使用以下方法重新加载它:
df = pd.read_pickle(file_name)
注意:在0.11.1之前,save和load是唯一的方法(现在已经过时,可以使用to_pickle和read_pickle代替)。
另一个流行的选择是使用HDF5(pytables),它为大型数据集提供了非常快速的访问时间:very fast。
import pandas as pd
store = pd.HDFStore('store.h5')
store['df'] = df # save it
store['df'] # load it
更高级的策略在食谱中讨论。
自从0.13版本起,还有msgpack,它可能更适用于互操作性,作为JSON的更快速的替代品,或者如果您有python对象/文本重的数据(请参见此问题)。
- Andy Hayden
11
13如果加载后需要转换数据(例如,将字符串/对象转换为datetime64),则在加载保存的CSV后仍需再次进行转换,这会导致性能损失。pickle以其当前状态保存数据帧,因此数据和其格式得到保留。这可以带来巨大的性能提升。 - harbun
4pickle和HDFStore都不能保存超过8GB的数据框,有其他替代方案吗? - user1700890
1@user1700890 尝试从随机数据(文本和数组)生成并发布一个新问题。我认为这可能不正确/怀疑我们漏掉了某些东西。新的问题会得到更多的关注,但请尝试包含/生成一个可以复制的DataFrame :) - Andy Hayden
1@YixingLiu 你可以在事后更改模式 https://dev59.com/wGQo5IYBdhLWcg3wMs4L#16249655 - Andy Hayden
3回复更新:自 Pandas v1.2 开始,
HDFStore 方法已更名为 to_hdf。 - yoursbh显示剩余6条评论
138
虽然已经有一些答案,但我找到了一个很好的比较,其中他们尝试了几种序列化Pandas DataFrames的方式:Efficiently Store Pandas DataFrames。
他们进行了比较: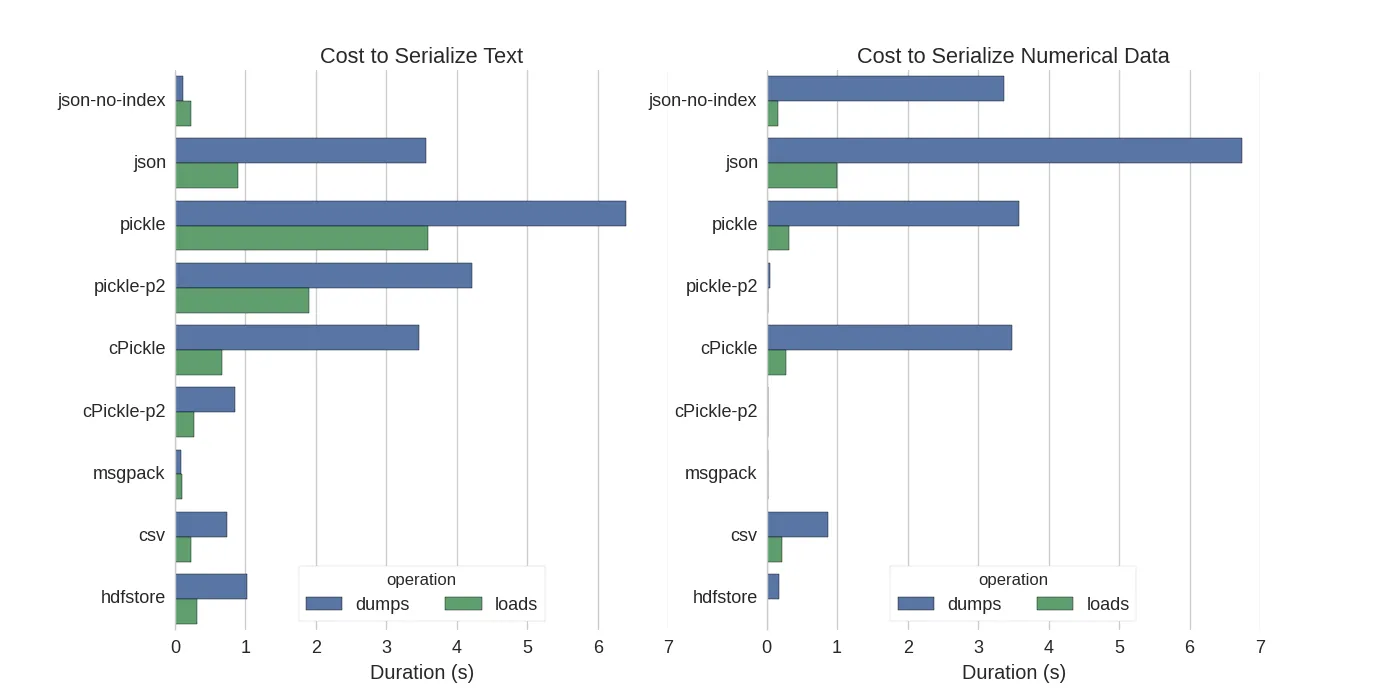 他们还提到,将文本数据转换为分类数据后,序列化会快得多。在他们的测试中,速度约快10倍(还请查看测试代码)。
他们还提到,将文本数据转换为分类数据后,序列化会快得多。在他们的测试中,速度约快10倍(还请查看测试代码)。
他们进行了比较:
- pickle:原始ASCII数据格式
- cPickle,一个C库
- pickle-p2:使用较新的二进制格式
- json:标准库json库
- json-no-index:类似于json,但没有索引
- msgpack:二进制JSON替代品
- CSV
- hdfstore:HDF5存储格式
他们所提及的测试源代码可在线上获得。由于该代码并不能直接工作,我做了一些小的改动,你可以在serialize.py中获得。我得到了以下结果:你不应该相信下面的内容适用于你的数据。你应该查看自己的数据并自己运行基准测试。
他们还提到,将文本数据转换为分类数据后,序列化会快得多。在他们的测试中,速度约快10倍(还请查看测试代码)。编辑:相对于CSV,pickle的加载时间更高可以通过所使用的数据格式来解释。默认情况下,pickle 使用可打印的ASCII表示形式,这会生成更大的数据集。然而,从图中可以看出,使用新的二进制数据格式(版本2,pickle-p2)的pickle具有更低的加载时间。
一些其他参考:
- 在问题“最快的Python库读取CSV文件”中,有一个非常详细的回答比较了不同的库读取CSV文件,并进行了基准测试。结果是使用
numpy.fromfile读取CSV文件是最快的。 - 另一个序列化测试显示,msgpack、ujson和cPickle在序列化方面最快。
- agold
8
1我更新了我的回答以解释你的问题。总结一下:默认情况下,pickle会以ASCII格式存储数据。 - agold
1谢谢您的解释!作为一条注记,pandas DataFrame 的 .to_pickle 看起来在使用 pkl.HIGHEST_PROTOCOL(应该是2)。 - ntg
2似乎上面链接的博客(高效存储Pandas数据框)已被删除。我自己使用
.to_pickle()(使用二进制存储)和.to_hdf()(无压缩)进行了比较。目标是速度,HDF的文件大小是Pickle的11倍,加载时间是Pickle的5倍。我的数据大约有5k个文件,每个文件大约有7k行x 6列,主要是数字。 - hamx0r3在我的测试中,相较于HDF,pickle 加载速度快了 5 倍,并且占用的磁盘空间只有 HDF 的 1/11(即 HDF 在磁盘上大了 11 倍,从磁盘加载所需的时间是 pickle 的 5 倍)。这些数据均基于 Python 3 和 Pandas 0.22.0。 - hamx0r
显示剩余3条评论
39
如果我理解正确,您已经使用了
pandas.read_csv(),但希望加快开发过程,以便在每次编辑脚本时不必重新加载文件,是这样吗?我有一些建议:
您可以使用
pandas.read_csv(..., nrows=1000)仅加载表的前面部分,在开发过程中使用。使用 ipython 进行交互式会话,使得您在编辑和重新加载脚本时保留 pandas 表在内存中。
将 CSV 转换为 HDF5 表格。
更新:使用
DataFrame.to_feather()和pd.read_feather()将数据存储在 R 兼容的 feather 二进制格式中,该格式超级快速(在我的手中,数值数据略快于pandas.to_pickle(),而字符串数据则快得多)。
您还可能对 stackoverflow 上的这个答案 感兴趣。
- Noah
2
你知道为什么
to_feather 在字符串数据上表现良好吗?我在我的数值数据框架上对 to_pickle 和 to_feature 进行了基准测试,结果 pickle 大约快了3倍。 - zyxue@zyxue 很好的问题,老实说我没有太多地使用过 feather 相关的东西,所以我没有答案。 - Noah
31
Pickle工作得很好!
import pandas as pd
df.to_pickle('123.pkl') #to save the dataframe, df to 123.pkl
df1 = pd.read_pickle('123.pkl') #to load 123.pkl back to the dataframe df
- Anbarasu
1
10请注意,生成的文件不是csv文件,建议使用@Andy Haydens的建议,使用扩展名
.pkl。 - agold12
你可以使用Feather格式文件,它非常快。
df.to_feather('filename.ft')
- Huanyu Liao
1
5数据可以用
feather库直接在R中使用。 - James Hirschorn6
Pandas数据框有一个名为
to_pickle的函数,可用于保存数据框:import pandas as pd
a = pd.DataFrame({'A':[0,1,0,1,0],'B':[True, True, False, False, False]})
print a
# A B
# 0 0 True
# 1 1 True
# 2 0 False
# 3 1 False
# 4 0 False
a.to_pickle('my_file.pkl')
b = pd.read_pickle('my_file.pkl')
print b
# A B
# 0 0 True
# 1 1 True
# 2 0 False
# 3 1 False
# 4 0 False
- mgoldwasser
2
另一个使用to_pickle()的新测试。
我一共有25个.csv文件需要处理,最终的dataframe大约包含2M条数据。
(注意:除了加载.csv文件外,我还会操作一些数据并通过新列扩展数据框。)
遍历所有25个.csv文件并创建数据框需要大约14秒。
从pkl文件中加载整个数据框只需要不到1秒。
- cs.lev
2
Numpy文件格式对于数值数据非常快速
我更喜欢使用numpy文件,因为它们快速且易于操作。 这里是一个简单的基准测试,用于保存和加载具有100万个点的1列数据框。
import numpy as np
import pandas as pd
num_dict = {'voltage': np.random.rand(1000000)}
num_df = pd.DataFrame(num_dict)
使用IPython的
%%timeit魔术函数。%%timeit
with open('num.npy', 'wb') as np_file:
np.save(np_file, num_df)
输出结果为:
100 loops, best of 3: 5.97 ms per loop
将数据加载回数据框中
%%timeit
with open('num.npy', 'rb') as np_file:
data = np.load(np_file)
data_df = pd.DataFrame(data)
输出结果为:
100 loops, best of 3: 5.12 ms per loop
不错!
缺点
如果你使用Python 2保存numpy文件,然后尝试在Python 3中打开(或反之亦然),就会出现问题。
- mark jay
1
6请注意,这种解决方案将删除您所有的列名并将所有整数数据更改为浮点数 :( - Joseph Garvin
1
https://docs.python.org/3/library/pickle.html
腌制协议格式:
协议版本0是原始的“人类可读”协议,与早期版本的Python向后兼容。
协议版本1是一种旧的二进制格式,也与早期版本的Python兼容。
协议版本2在Python 2.3中引入。它提供了新式类的更高效的腌制。请参阅PEP 307以获取有关协议2带来的改进的信息。
协议版本3在Python 3.0中添加。它明确支持字节对象,并且无法由Python 2.x取消腌制。这是默认协议,并且在需要与其他Python 3版本兼容性时推荐使用。
协议版本4在Python 3.4中添加。它增加了对非常大的对象的支持,腌制更多种类的对象和一些数据格式优化。请参阅PEP 3154以获取有关协议4带来的改进的信息。
- Gilco
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接