为什么在编程语言如Java中,数组索引使用0而不是1进行操作?我对Java完全陌生,欢迎任何解释。
为什么Java中的数组索引从0开始?
11
- Shashank Agarwal
4
4我认为Java语言的设计者只是想让它与C++保持紧密联系,这样他们就可以轻松地迁移到Java。 - Leo
7请参考为何零起点数组是标准?来查看已经回答过的问题。 - DavidPostill
同时,http://developeronline.blogspot.com.br/2008/04/why-array-index-should-start-from-0.html - Leo
1数组索引是元素之间的空间,而不是元素本身。 “0号”索引是第一个元素之前的空格。 在一个三个元素的数组中,索引2(长度-1)指的是第三个——也就是最后一个——元素。 - aliteralmind
6个回答
27
Java使用零基索引是因为 C 语言使用了零基索引。C语言采用零基索引是因为数组索引不过是内存偏移量,因此数组的第一个元素就在其指向内存的位置上,*(array+0)。
还可参考维基百科的各种语言中的数组索引?
- Kevin
25
对于 @Kevin的回答,我想引用Programmers.SE上的一个回答来进一步说明:
数组中的索引实际上不是索引。它只是距离数组开头的偏移量。第一个元素位于数组的开始位置,因此没有距离。因此,偏移量为0。
此外,如果您想了解不同语言如何进行数组索引,请查看维基百科上的这个详尽列表。
- Engineer2021
10
Dijkstra在为什么编号应该从零开始(1982)中说:
当处理长度为N的序列时,我们希望通过下标来区分其元素,接下来令人烦恼的问题是要为起始元素分配什么下标值。遵循惯例a)会得到下标范围1 ≤ i < N+1;然而,从0开始则会得到更好的范围0 ≤ i < N。因此,让我们将序数从零开始:一个元素的序数(下标)等于它前面的元素数量。故事的寓意是,在经过那么多世纪之后,我们最好把零看作是一个非常自然的数字。
有关这篇文章的讨论可以在Lambda the Ultimate - Why numbering should start at 0中找到。
- kapex
10
3有趣的引语。以下标1开始,下标范围等同于“1 <= i <= N”,因此Dijkstra的论点并不特别令人信服。 - jII
1@jesterII:1 ≤ i < N+1,但你可以有效地将范围设定为任何值。 - Engineer2021
2这只是一种观点。唯一真正的答案是“因为语言是按照这种方式设计的”。 - Stefano Sanfilippo
3他可能会给出与Knuth相同的答案:http://xkcd.com/163/ - kapex
@Kapep,这是Knuth的一句非常重要的名言。在我看来,关于从0或1开始的引用不应该被过分认真对待,我相信Knuth和Dijkstra都有更有趣的话要说;) - 463035818_is_not_a_number
显示剩余5条评论
4
我已经在下面的图表中回答了这个问题,我用一张纸写了自解释的内容。
主要步骤:
1. 创建引用 2. 实例化数组 3. 分配数据到数组
主要步骤:
1. 创建引用 2. 实例化数组 3. 分配数据到数组
----------
- 请注意,当数组刚被实例化时...默认情况下,所有块都分配了零,直到我们为其分配值
- 数组从零开始,因为第一个地址将指向引用(即-图像中的X102+0)
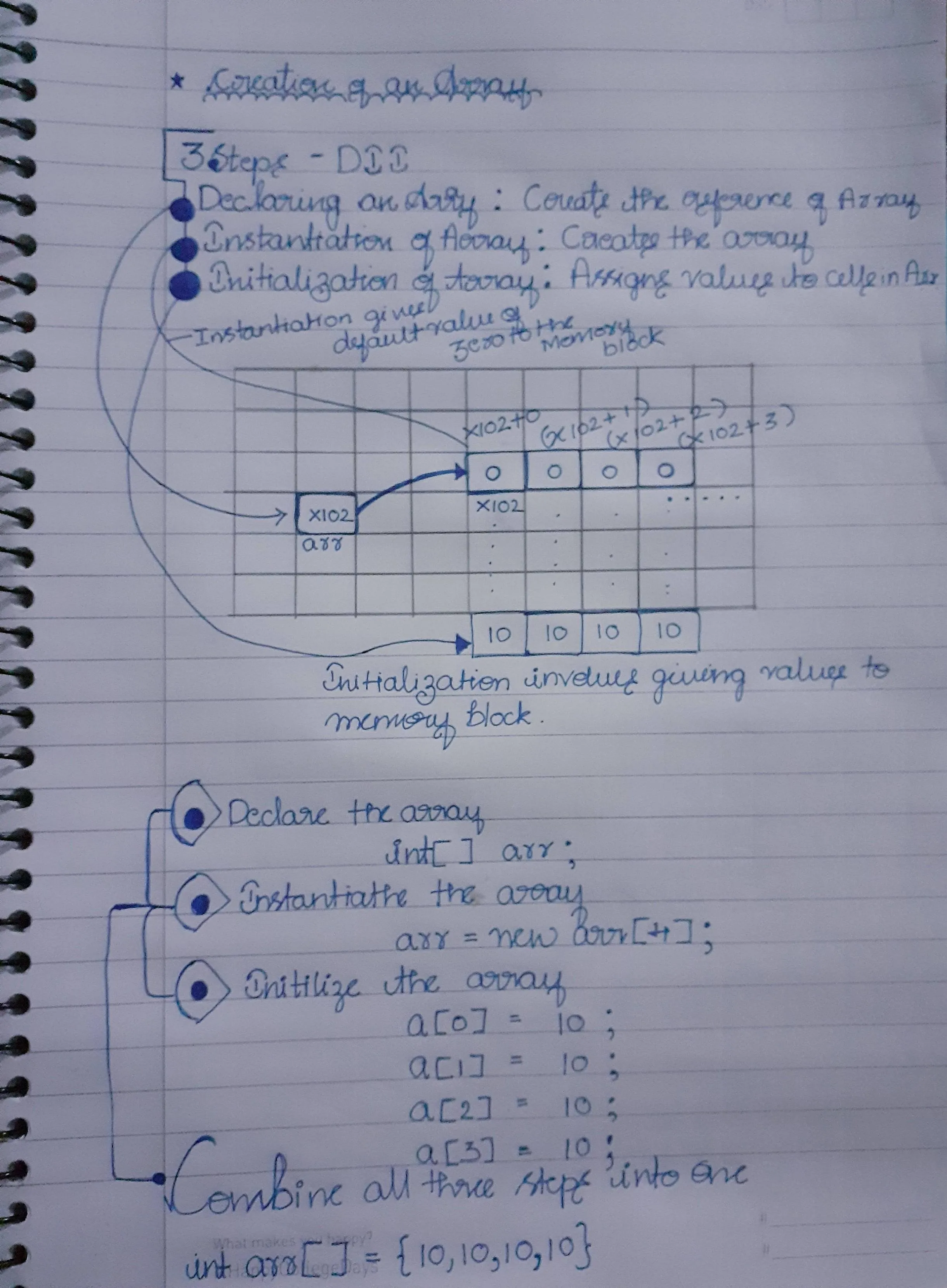
我也在这里发布了这个答案 这里
- Devrath
0
总结他的论点:
在处理自然数的子序列时,上限和下限之间的差应该是子序列的长度。数组的索引可以被视为这种特殊类型的子序列。 下限应该是包含的,上限应该是排除的。换句话说,下限应该是数组的第一个索引。否则,我们可能需要在某些子序列中使用非自然数的下限。 如果我们想要保持条件(1)和(2),那么我们对上限和下限实际上有两个选择:1 <= i < N+1 或 0 <= i < N。显然,将N+1放入范围内很丑陋,因此我们应该优先从0开始索引。
- moeez shem
-2
这一切都是遗留问题,源于编程语言如C只是高级汇编语言的时代。编程大师们花费了他们美好的生命来做指针算术,以至于从零开始计数已经成为他们的第二天性。现在,他们将这种遗产传承给了许多现代语言。
你甚至可以把语句读作“零是最自然的数字”。零不是自然数。人们在现实生活中不从零开始计数,数学家不这样做,物理学家不这样做,统计学家也不从零开始计数……只有计算机科学这样做。
此外,你不会说“我有零个苹果”来表达你没有任何苹果的事实,否则按照同样的逻辑,你会说“我没有负一个苹果”来表达你有一个苹果的事实 :P
- user2041042
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接