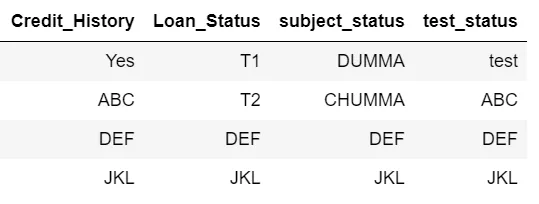
我有一个数据框,如下所示。
df = pd.DataFrame({'Credit_History':['Yes','ABC','DEF', 'JKL'],
'Loan_Status':['T1','T2',np.nan,np.nan],
'subject_status':['DUMMA','CHUMMA',np.nan,np.nan],
'test_status':['test',np.nan,np.nan,np.nan]})
我的目标是使用相应的信用历史值填充所有行和列中的缺失值。
我尝试了下面的方法,但它不起作用。
cols = ['Loan_Status','subject_status','test_status']
df[cols] = df[cols].fillna(df['Credit_History'])
我希望我的输出结果如下所示。基本上,无论哪一行缺失,它都应该从credit_history列中选择相应的值。