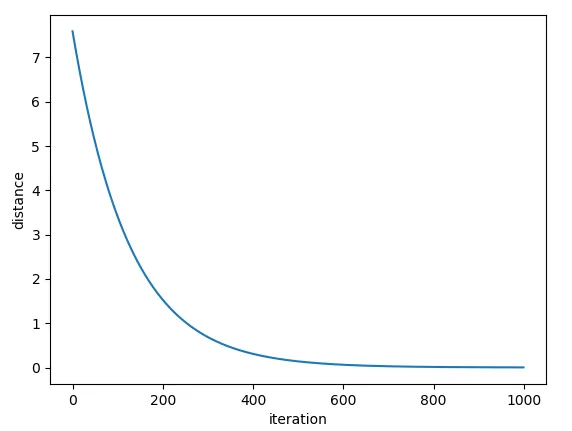
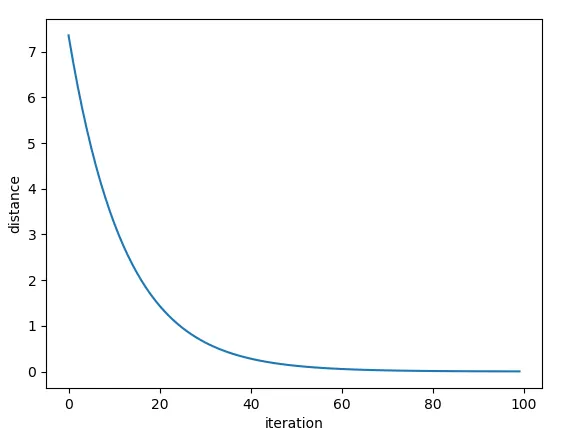
开始学习PyTorch,尝试做一些非常简单的事情,试图将一个随机初始化的大小为5的向量移动到目标向量[1,2,3,4,5]。
但是我的距离没有减小!而且我的向量x变得疯狂。不知道我漏掉了什么。
但是我的距离没有减小!而且我的向量x变得疯狂。不知道我漏掉了什么。
import torch
import numpy as np
from torch.autograd import Variable
# regress a vector to the goal vector [1,2,3,4,5]
dtype = torch.cuda.FloatTensor # Uncomment this to run on GPU
x = Variable(torch.rand(5).type(dtype), requires_grad=True)
target = Variable(torch.FloatTensor([1,2,3,4,5]).type(dtype),
requires_grad=False)
distance = torch.mean(torch.pow((x - target), 2))
for i in range(100):
distance.backward(retain_graph=True)
x_grad = x.grad
x.data.sub_(x_grad.data * 0.01)