这是一个奇怪的难题。我从古登堡项目下载了两个文本文件 - 《爱丽丝梦游仙境》和《尤利西斯》。
在《爱丽丝梦游仙境》中,停用词已经被去除了,但是在《尤利西斯》中仍然存在。
即使使用 "filter (!word %in% stop_words$word)" 替换 "anti_join",这个问题仍然存在。
我该如何将《尤利西斯》中的停用词去除?
感谢您的帮助!
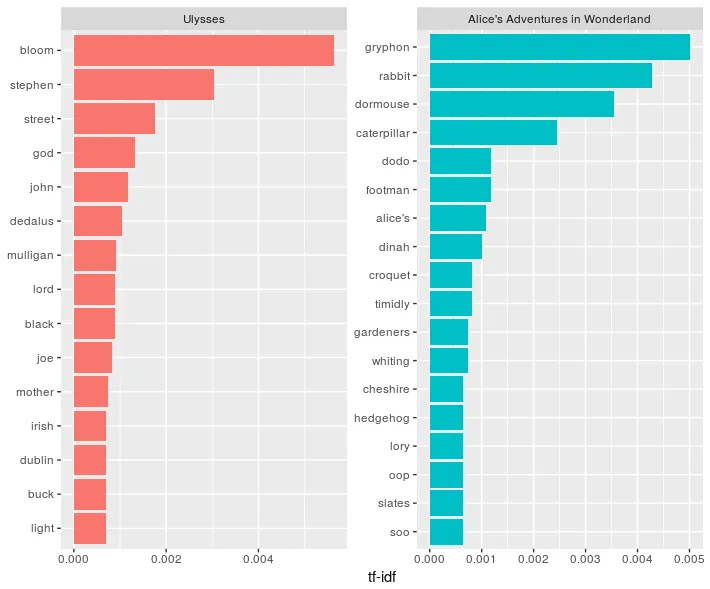
阅读《爱丽丝梦游仙境》和《尤利西斯》的前15个tf_idf的图表请点击此处。
我该如何将《尤利西斯》中的停用词去除?
感谢您的帮助!
阅读《爱丽丝梦游仙境》和《尤利西斯》的前15个tf_idf的图表请点击此处。
library(gutenbergr)
library(dplyr)
library(stringr)
library(tidytext)
library(ggplot2)
titles <- c("Alice's Adventures in Wonderland", "Ulysses")
books <- gutenberg_works(title %in% titles) %>%
gutenberg_download(meta_fields = c("title", "author"))
data(stop_words)
tidy_books <- books %>%
unnest_tokens(word, text) %>%
anti_join(stop_words) %>%
count(title, word, sort=TRUE) %>%
ungroup()
plot_tidy_books <- tidy_books %>%
bind_tf_idf(word, title, n) %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
mutate(title = factor(title, levels = unique(title)))
plot_tidy_books %>%
group_by(title) %>%
arrange(desc(n))%>%
top_n(15, tf_idf) %>%
mutate(word=reorder(word, tf_idf)) %>%
ggplot(aes(word, tf_idf, fill=title)) +
geom_col(show.legend = FALSE) +
labs(x=NULL, y="tf-idf") +
facet_wrap(~title, ncol=2, scales="free") +
coord_flip()
{kind=link}