我有一个包含错误信息的数据框需要修正:
import pandas as pd
tuples_index = [(1,1990), (2,1999), (2,2002), (3,1992), (3,1994), (3,1996)]
index = pd.MultiIndex.from_tuples(tuples_index, names=['id', 'FirstYear'])
df = pd.DataFrame([2007, 2006, 2006, 2000, 2000, 2000], index=index, columns=['LastYear'] )
df
Out[4]:
LastYear
id FirstYear
1 1990 2007
2 1999 2006
2002 2006
3 1992 2000
1994 2000
1996 2000
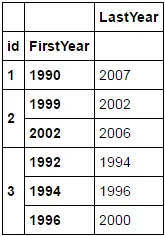
id是指一个商业,而这个DataFrame是一个更大的示例切片的一部分,展示了一个商业如何移动。每个记录都是一个唯一的位置,并且我想捕捉它在那里的第一年和最后一年。当前的“LastYear”对于只有一个记录的企业是准确的,并且对于拥有多个记录的企业的最新记录也是准确的。最终df应该是这样的:
LastYear
id FirstYear
1 1990 2007
2 1999 2002
2002 2006
3 1992 1994
1994 1996
1996 2000
我用的方法非常笨拙:
multirecord = df.groupby(level=0).filter(lambda x: len(x) > 1)
multirecord_grouped = multirecord.groupby(level=0)
ls = []
for _, group in multirecord_grouped:
levels = group.index.get_level_values(level=1).tolist() + [group['LastYear'].iloc[-1]]
ls += levels[1:]
multirecord['LastYear'] = pd.Series(ls, index=multirecord.index.copy())
final_joined = pd.concat([df.groupby(level=0).filter(lambda x: len(x) == 1),multirecord]).sort_index()
有更好的方法吗?