这是我正在尝试优化的Cython代码:
import cython
cimport cython
from libc.stdlib cimport rand, srand, RAND_MAX
import numpy as np
cimport numpy as np
def genLoans(int loanid):
cdef int i, j, k
cdef double[:,:,:] loans = np.zeros((240, 20, 1000))
cdef double[:,:] aggloan = np.zeros((240, 20))
for j from 0<=j<1000:
srand(loanid*1000+j)
for i from 0<=i<240:
for k from 0<=k<20:
loans[i,k,j] = rand()
###some other logics
aggloan[i,k] += loans[i,k,j]/1000
return aggloan
cython -a 展示
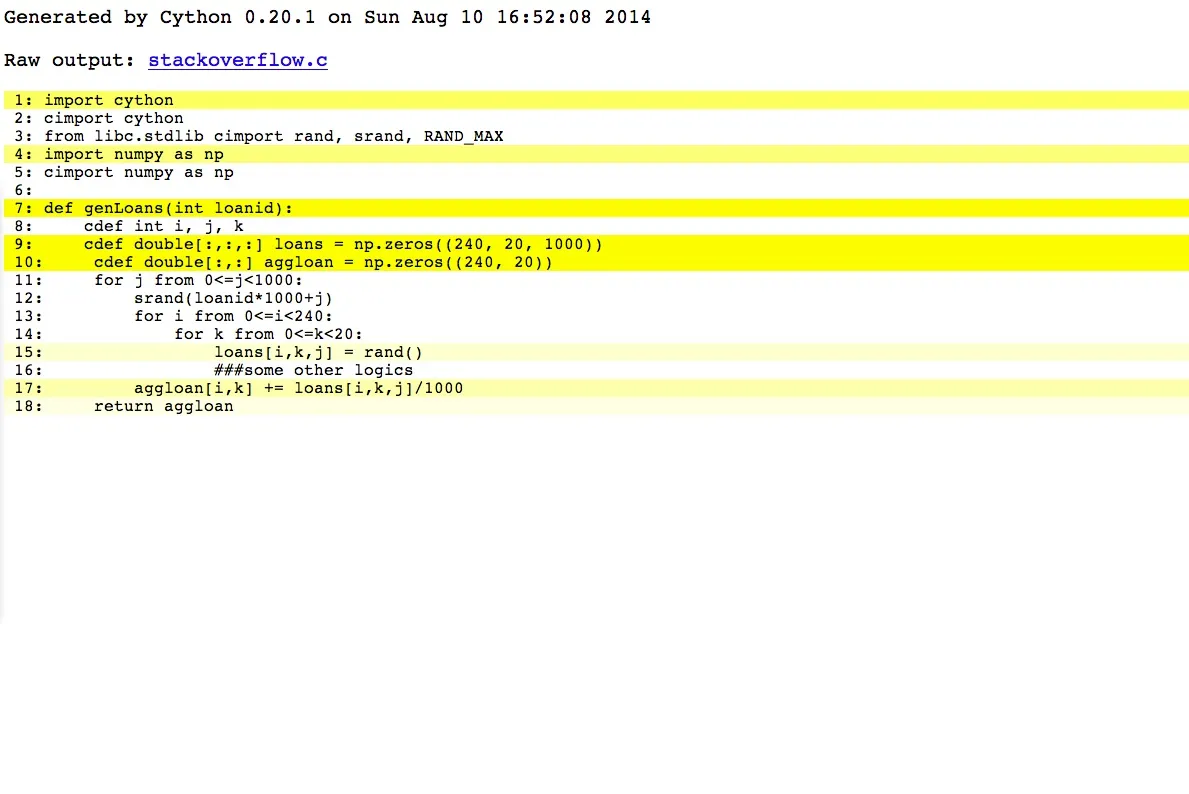 我猜当我试着初始化零数组loans和aggloan时,numpy会减慢我的速度。然而,我需要运行5000多个贷款。只是想知道在定义3D / 2D并返回数组时是否有其他避免使用numpy的方法...
我猜当我试着初始化零数组loans和aggloan时,numpy会减慢我的速度。然而,我需要运行5000多个贷款。只是想知道在定义3D / 2D并返回数组时是否有其他避免使用numpy的方法...