我正在尝试在Keras中为时间序列开发一个编码器模型。数据的形状为(5039,28,1),这意味着我的seq_len为28,只有一个特征。对于编码器的第一层,我使用112个隐藏单元,第二层将有56个单元,并且为了能够返回解码器的输入形状,我不得不添加第三层具有28个隐藏单元(这个自编码器应该重构其输入)。但我不知道连接LSTM层的正确方法是什么。据我所知,我可以添加RepeatVector或return_seq=True。您可以在以下代码中看到我的两个模型。我想知道它们之间的区别以及哪种方法是正确的?
使用return_sequence=True的第一个模型:
inputEncoder = Input(shape=(28, 1))
firstEncLayer = LSTM(112, return_sequences=True)(inputEncoder)
snd = LSTM(56, return_sequences=True)(firstEncLayer)
outEncoder = LSTM(28)(snd)
context = RepeatVector(1)(outEncoder)
context_reshaped = Reshape((28,1))(context)
encoder_model = Model(inputEncoder, outEncoder)
firstDecoder = LSTM(112, return_sequences=True)(context_reshaped)
outDecoder = LSTM(1, return_sequences=True)(firstDecoder)
autoencoder = Model(inputEncoder, outDecoder)
使用RepeatVector的第二个模型:
inputEncoder = Input(shape=(28, 1))
firstEncLayer = LSTM(112)(inputEncoder)
firstEncLayer = RepeatVector(1)(firstEncLayer)
snd = LSTM(56)(firstEncLayer)
snd = RepeatVector(1)(snd)
outEncoder = LSTM(28)(snd)
encoder_model = Model(inputEncoder, outEncoder)
context = RepeatVector(1)(outEncoder)
context_reshaped = Reshape((28, 1))(context)
firstDecoder = LSTM(112)(context_reshaped)
firstDecoder = RepeatVector(1)(firstDecoder)
sndDecoder = LSTM(28)(firstDecoder)
outDecoder = RepeatVector(1)(sndDecoder)
outDecoder = Reshape((28, 1))(outDecoder)
autoencoder = Model(inputEncoder, outDecoder)
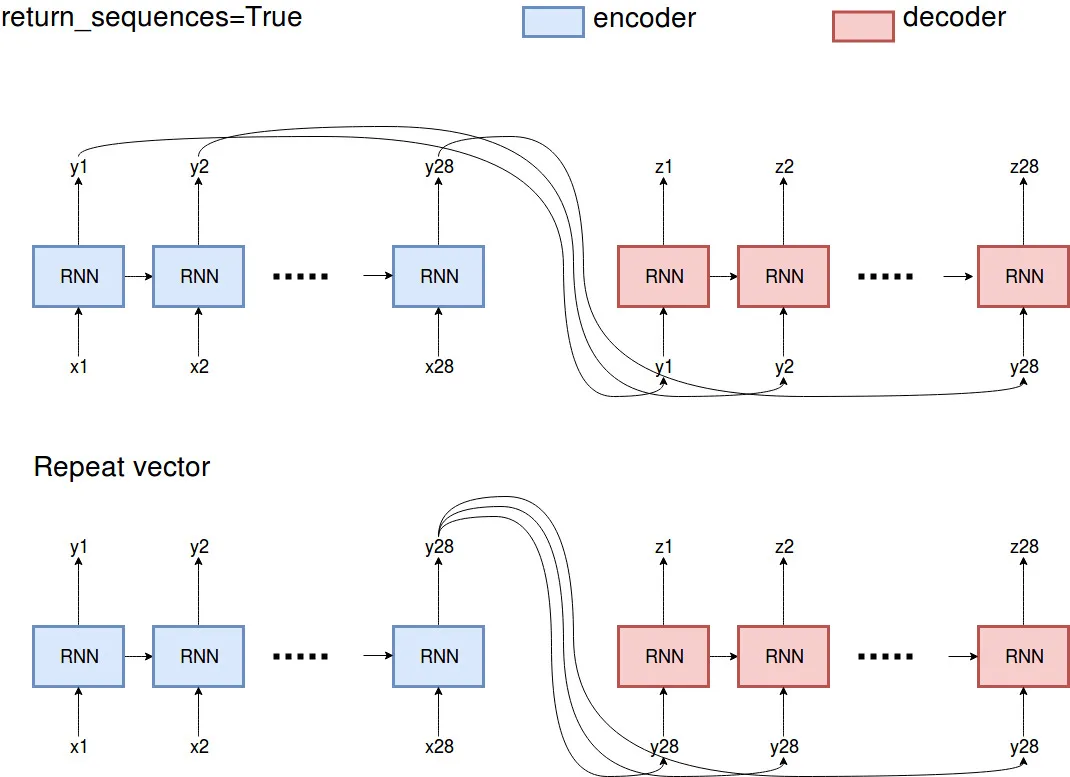
RepeatVector(1)的原因是什么?你只是用它来添加一个时间维度为“1”吗?但是随后你又使用了Reshape((28, 1))并将其取消了... 还是我在你的代码中有什么误解了? - Super-intelligent Shade