我有点超纲了(最好的方式就是这样),但我正在探索一种优化方法,可以减少我的应用程序中GPU到CPU数据传输的量。
我的应用程序在GPU中对顶点数据进行一些修改。偶尔,CPU必须读回部分修改后的顶点数据,然后计算一些参数,这些参数通过uniforms传递回GPU着色器,形成一个循环。
将所有顶点数据传回CPU并在CPU上筛选(数百万个点)需要太长时间,因此我采取了“hack”来减少工作量以使其可用,尽管不是最优的。
我所做的:
1. CPU:读取图像 2. CPU:为每个像素生成1个顶点,Z基于颜色信息/过滤器等。 3. CPU:将所有顶点数据传输到GPU。 4. GPU:使用变换反馈实时更新GL_POINT顶点坐标,基于从CPU设置的一些统一参数。
当我只想读取矩形“部分”时,我使用glMapBufferRange将组成所需矩形的整行映射(警告:糟糕的图表)。
有人知道一种聪明的方法可以高效地获取红色,而不需要蓝色吗?(不需要发出一系列的glMapBufferRange调用)
编辑-
使用情况是,我将图像渲染成GLPoints,并在Z中根据颜色信息进行着色和偏移(根据距离进行大小等)。然后用户可以使用鼠标光标刷修改顶点Z数据。一些刷子应用代码背后的逻辑需要知道鼠标下方区域(刷圆)的Z,例如最小/最大/平均值等,以便CPU可以通过设置一系列馈入着色器的统一变量来控制数据的着色器修改。因此,例如,用户可以说,我希望所有在光标下的点都设置为平均值。这可能完全可以在GPU中完成,但想法是一旦我得到了CPU-GPU“循环”(尽可能优化),我就可以将min/max/avg等扩展到CPU上做一些有趣的事情,这可能会很麻烦(可能)完全在GPU上完成。
我的应用程序在GPU中对顶点数据进行一些修改。偶尔,CPU必须读回部分修改后的顶点数据,然后计算一些参数,这些参数通过uniforms传递回GPU着色器,形成一个循环。
将所有顶点数据传回CPU并在CPU上筛选(数百万个点)需要太长时间,因此我采取了“hack”来减少工作量以使其可用,尽管不是最优的。
我所做的:
1. CPU:读取图像 2. CPU:为每个像素生成1个顶点,Z基于颜色信息/过滤器等。 3. CPU:将所有顶点数据传输到GPU。 4. GPU:使用变换反馈实时更新GL_POINT顶点坐标,基于从CPU设置的一些统一参数。
当我只想读取矩形“部分”时,我使用glMapBufferRange将组成所需矩形的整行映射(警告:糟糕的图表)。
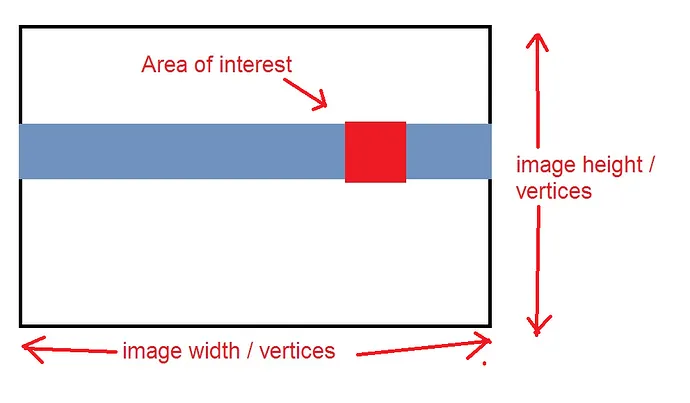
有人知道一种聪明的方法可以高效地获取红色,而不需要蓝色吗?(不需要发出一系列的glMapBufferRange调用)
编辑-
使用情况是,我将图像渲染成GLPoints,并在Z中根据颜色信息进行着色和偏移(根据距离进行大小等)。然后用户可以使用鼠标光标刷修改顶点Z数据。一些刷子应用代码背后的逻辑需要知道鼠标下方区域(刷圆)的Z,例如最小/最大/平均值等,以便CPU可以通过设置一系列馈入着色器的统一变量来控制数据的着色器修改。因此,例如,用户可以说,我希望所有在光标下的点都设置为平均值。这可能完全可以在GPU中完成,但想法是一旦我得到了CPU-GPU“循环”(尽可能优化),我就可以将min/max/avg等扩展到CPU上做一些有趣的事情,这可能会很麻烦(可能)完全在GPU上完成。
干杯!Laythe
glMapBufferRange正在将数据复制到CPU。虽然这确实是映射的可能实现方式之一,但一般来说,映射的目的是直接访问可由GPU访问的内存。因此,映射多大的范围并不重要;重要的是GPU需要做多少同步才能使该数据可见。 - Nicol Bolas