Pandas 的样式关键字仅适用于行或列。是否可以按子级拆分它。
例如
np.random.seed(24)
df = pd.DataFrame({'Types': np.linspace(1, 10, 10)})
df = pd.concat([df, pd.DataFrame(np.random.randn(10, 4), columns=['Names','V1','V2','V3'])],
axis=1)
df['Types'][0:7] ="Dang"
df['Types'][7:] ="Fang"
df['Names'][0:3] ="Andy"
df['Names'][3:8] ="Flower"
df['Names'][8:] ="Avril"
df2 = pd.groupby(df,['Types','Names']).mean()
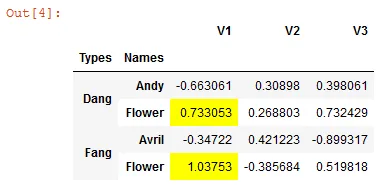
df2
现在我想根据子级别突出显示最大值。
def highlight_max(x):
return ['background-color: yellow' if v == x.max() else ''
for v in x]
df2.style.apply(highlight_max,axis=0,subset=['V1'])
在这种情况下,它将突出显示“V1”列中的最大值。根据组级别,我希望基本上有两个最大值。因此,我想要突出显示这些值。是否有简单的方法来做到这一点?没有任何介绍材料涵盖了这个基本功能。