我正在尝试移除名字字符串末尾的中间名缩写。数据看起来像这样:
df = pd.DataFrame({'Name': ['Smith, Jake K',
'Howard, Rob',
'Smith-Howard, Emily R',
'McDonald, Jim T',
'McCormick, Erica']})
我目前使用的以下代码对所有姓名均有效,但无法正确处理 "McCormick, Erica"。我首先使用正则表达式来识别所有大写字母,然后将任何有三个或更多大写字母的行中从字符串中删除 [:-1](尝试删除中间的名字和额外空格)。
df['Cap_Letters'] = df['Name'].str.findall(r'[A-Z]')
df.loc[df['Cap_Letters'].str.len() >= 3, 'Name'] = df['Name'].str[:-1]
以下是输出结果:
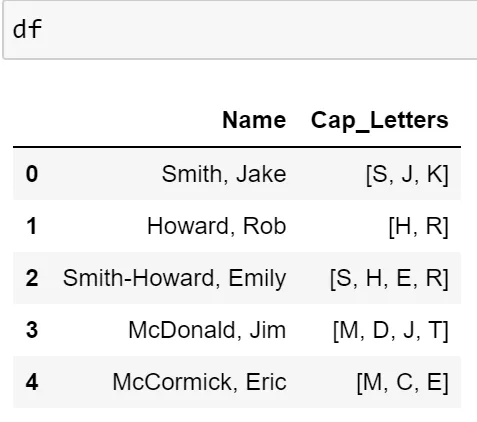
正如您所看到的,这将正确地删除除McCormick, Erica之外所有姓名的中间名称缩写。 原因是她有3个大写字母但没有中间名称缩写,这会错误地删除Erica中的'a'。
split方法吗? - JoshuaF