当我搜索像
.NET,
C++,
C#和
C这样的单词时,我遇到了更严重的问题。你会认为程序员们应该知道如何为正则表达式命名,但实际上很难做到。
总之,这就是我从
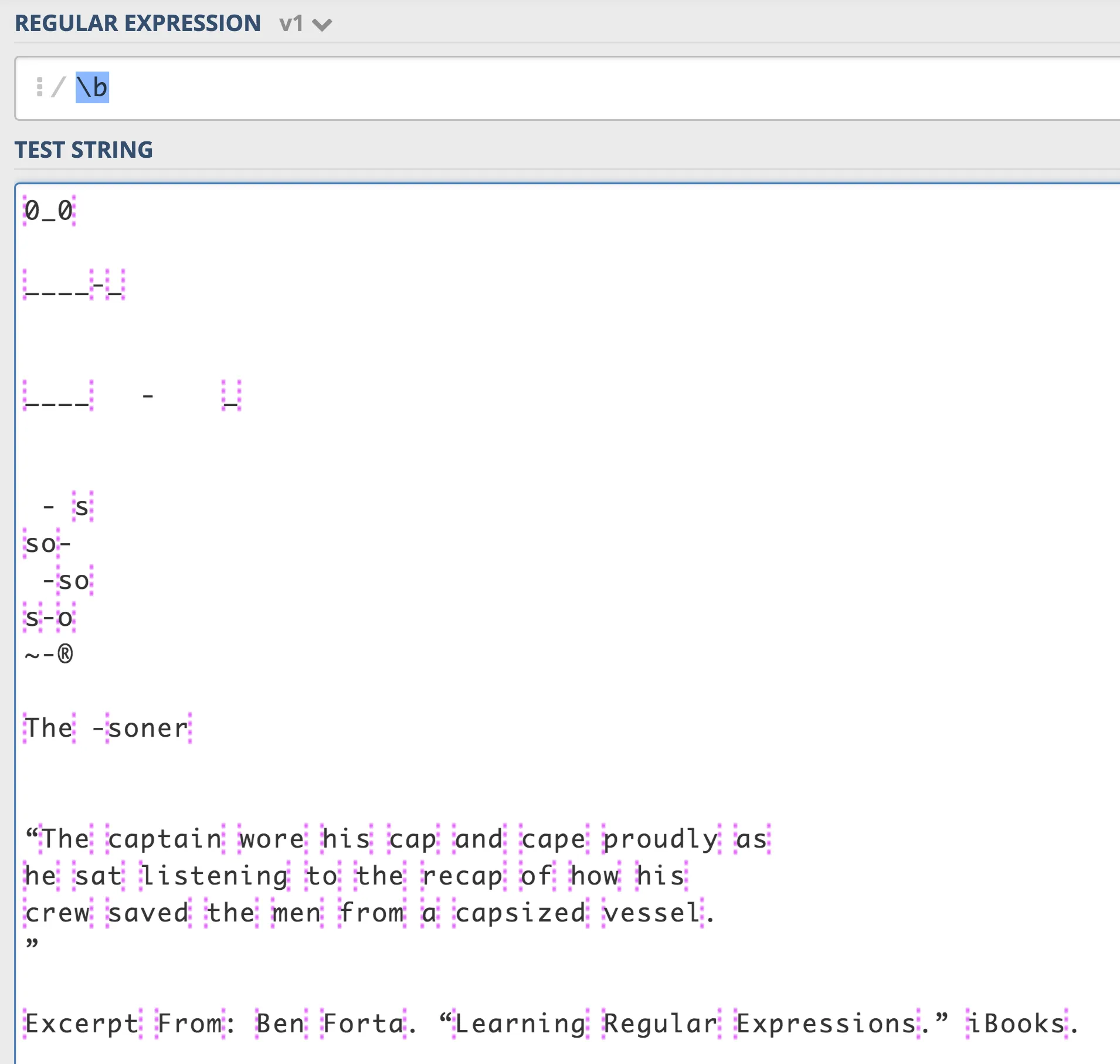
http://www.regular-expressions.info(一个很棒的网站)总结出来的:在大多数正则表达式中,由简写字符类
\w匹配的字符是被单词边界视为单词字符的字符。Java是个例外。Java支持
\b的Unicode,但不支持
\w的Unicode(我相信当时有一个很好的理由)。
\w代表"word character",它总是匹配ASCII字符
[A-Za-z0-9_],注意下划线和数字(但不包括破折号!)。在大多数支持Unicode的正则表达式中,
\w包括许多其他脚本中的字符。有很多关于哪些字符实际上被包括在内的不一致性。通常都包括字母脚本和表意文字中的字母和数字。连接符标点符号,除了下划线和不是数字的数字符号,可能被包括或不被包括。XML模式和XPath甚至包括
\w中的所有符号。但是Java、JavaScript和PCRE只匹配带ASCII字符的
\w。
这就是为什么在基于Java的正则表达式搜索
C++,
C#或
.NET时(即使你记得转义句点和加号),
\b也会失灵。
注意:我不确定如何处理文本中的错误,比如某人在句子末尾的句点后面没有空格。我允许它发生,但我不确定这是正确的做法。
总之,在Java中,如果你要搜索这些奇怪命名的编程语言,你需要将
\b替换为前后都有空格和标点符号的设计器。例如:
public static String grep(String regexp, String multiLineStringToSearch) {
String result = "";
String[] lines = multiLineStringToSearch.split("\\n");
Pattern pattern = Pattern.compile(regexp);
for (String line : lines) {
Matcher matcher = pattern.matcher(line);
if (matcher.find()) {
result = result + "\n" + line;
}
}
return result.trim();
}
然后在你的测试或主函数中:
String beforeWord = "(\\s|\\.|\\,|\\!|\\?|\\(|\\)|\\'|\\\"|^)";
String afterWord = "(\\s|\\.|\\,|\\!|\\?|\\(|\\)|\\'|\\\"|$)";
text = "Programming in C, (C++) C#, Java, and .NET.";
System.out.println("text="+text);
System.out.println("Bad word boundary can't find because of Java: grep with word boundary for .NET="+ grep("\\b\\.NET\\b", text));
System.out.println("Should find: grep exactly for .NET="+ grep(beforeWord+"\\.NET"+afterWord, text));
System.out.println("Bad word boundary can't find because of Java: grep with word boundary for C#="+ grep("\\bC#\\b", text));
System.out.println("Should find: grep exactly for C#="+ grep("C#"+afterWord, text));
System.out.println("Bad word boundary can't find because of Java:grep with word boundary for C++="+ grep("\\bC\\+\\+\\b", text));
System.out.println("Should find: grep exactly for C++="+ grep(beforeWord+"C\\+\\+"+afterWord, text));
System.out.println("Should find: grep with word boundary for Java="+ grep("\\bJava\\b", text));
System.out.println("Should find: grep for case-insensitive java="+ grep("?i)\\bjava\\b", text));
System.out.println("Should find: grep with word boundary for C="+ grep("\\bC\\b", text));
text = "Worked on C&O (Chesapeake and Ohio) Canal when I was younger; more recently developed in Lisp.";
System.out.println("text="+text);
System.out.println("Bad word boundary because of C name: grep with word boundary for C="+ grep("\\bC\\b", text));
System.out.println("Should be blank: grep exactly for C="+ grep(beforeWord+"C"+afterWord, text));
text = "C is a language that should have been named differently.";
System.out.println("text="+text);
System.out.println("grep exactly for C="+ grep(beforeWord+"C"+afterWord, text));
text = "One language that should have been named differently is C";
System.out.println("text="+text);
System.out.println("grep exactly for C="+ grep(beforeWord+"C"+afterWord, text));
text = "The letter 'c' can be hard as in Cat, or soft as in Cindy. Computer languages should not require disambiguation (e.g. Ruby, Python vs. Fortran, Hadoop)";
System.out.println("text="+text);
System.out.println("Should be blank: grep exactly for C="+ grep(beforeWord+"C"+afterWord, text));
顺便感谢一下http://regexpal.com/,如果没有它,正则表达式的世界将会很悲惨!