我有关于异常值检测的几个问题:
我们能否使用k-means算法找到异常值,这是一个好方法吗?
是否有任何无需用户输入的聚类算法?
我们能否使用支持向量机或其他监督学习算法进行异常值检测?
每种方法的优缺点是什么?
我有关于异常值检测的几个问题:
我们能否使用k-means算法找到异常值,这是一个好方法吗?
是否有任何无需用户输入的聚类算法?
我们能否使用支持向量机或其他监督学习算法进行异常值检测?
每种方法的优缺点是什么?
我将限制自己,只谈论我认为对解答你的问题至关重要的内容,因为这个话题已经有很多教科书在涉及,并且可能最好分开提出不同的问题来讨论。
I wouldn't use k-means for spotting outliers in a multivariate dataset, for the simple reason that the k-means algorithm is not built for that purpose: You will always end up with a solution that minimizes the total within-cluster sum of squares (and hence maximizes the between-cluster SS because the total variance is fixed), and the outlier(s) will not necessarily define their own cluster. Consider the following example in R:
set.seed(123)
sim.xy <- function(n, mean, sd) cbind(rnorm(n, mean[1], sd[1]),
rnorm(n, mean[2],sd[2]))
# generate three clouds of points, well separated in the 2D plane
xy <- rbind(sim.xy(100, c(0,0), c(.2,.2)),
sim.xy(100, c(2.5,0), c(.4,.2)),
sim.xy(100, c(1.25,.5), c(.3,.2)))
xy[1,] <- c(0,2) # convert 1st obs. to an outlying value
km3 <- kmeans(xy, 3) # ask for three clusters
km4 <- kmeans(xy, 4) # ask for four clusters
从下图中可以看出,异常值永远不会被单独恢复:它总是属于其他簇之一。
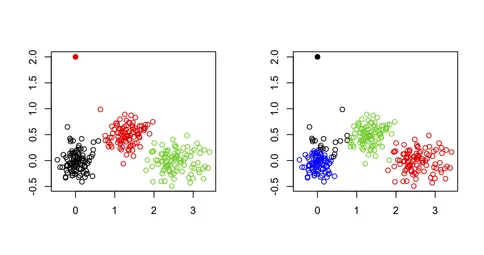
然而,有可能采用两阶段方法,以迭代方式去除极端点(在这里定义为远离它们的聚类中心的向量),如下文所述:通过去除异常值来改进K-Means(Hautamäki等人)。
这与遗传研究中检测和去除表现出基因分型误差的个体或兄弟/双胞胎(或者当我们想要识别人群亚结构时)的做法有些相似,而我们只想保留不相关的个体;在这种情况下,我们使用多维缩放(等价于PCA,对于前两个轴来说只是一个常数)并删除在任何一条顶部10或20轴上超过6个标准差的观测值(例如,请参见人口结构和特征分析,Patterson等人,PLoS遗传学 2006年2月(12))。
一个常见的替代方案是使用有序的稳健马氏距离进行绘图(在QQ图中)与预期的自由度为卡方分布的分位数进行比较,如下文所述:
R.G. Garrett(1989)。卡方图:一种多元异常值识别工具。 地球化学勘探杂志 32(1/3):319-341。
(这个功能可以在mvoutlier R包中使用。)
Handl,J.,Knowles,J.和Kell,D.B。 (2005)。计算后基因组数据分析中的聚类验证。 Bioinformatics 21(15):3201-3212。
我在Cross Validated上讨论过,其中提供了良好的概述。例如,您可以在数据的不同随机样本(使用引导)上运行算法的多个实例,针对一定范围的聚类数(例如,k = 1到20),并根据被考虑的优化标准选择k(平均轮廓宽度,共辉相关性等);它可以完全自动化,无需用户输入。
存在其他形式的聚类,基于密度(集群被视为对象异常常见的区域)或分布(集群是遵循给定概率分布的对象集)。例如,Mclust 中实现的基于模型的聚类允许通过跨越变化数量的聚类和选择最佳模型来识别多元数据集中的集群。根据BIC标准,可以对协方差矩阵的形状范围进行扩展。
其他用于无监督、半监督或有监督学习的方法可以在谷歌上轻松找到,例如:
相关主题是异常检测,您会发现很多论文。
1)我们能使用k-means算法来发现异常值吗?这是一个好方法吗?
基于聚类的方法最适合发现聚类,也可以用来检测异常值。在聚类过程中,异常值会影响聚类中心的位置,甚至会作为微型聚类聚合在一起。这些特点使得基于聚类的方法难以应用于复杂的数据库。
2)是否有任何聚类算法不需要用户提供任何输入?
你可能会在这个主题上获得一些有价值的知识: Dirichlet过程聚类
基于Dirichlet的聚类算法可以根据观察数据的分布自适应地确定聚类数量。
3)我们是否可以使用支持向量机或其他监督学习算法来进行异常值检测?
任何监督学习算法都需要足够的标记训练数据来构建分类器。然而,在现实世界的问题中并不总是有平衡的训练数据集,例如入侵检测、医学诊断等。根据Hawkins异常值("Identification of Outliers". Chapman and Hall, London, 1980)的定义,正常数据的数量远大于异常值的数量。大多数监督学习算法无法在上述不平衡的数据集上实现高效的分类器。
4)每种方法的利弊是什么?
在过去的几十年中,有关异常值检测的研究从全局计算到局部分析,异常值的描述从二进制解释到概率表示不一而足。根据异常值检测模型的假设,异常值检测算法可以分为四类:基于统计的算法、基于聚类的算法、最近邻算法和基于分类器的算法。以下是一些有价值的异常值检测调查:
Hodge, V. and Austin, J. "A survey of outlier detection methodologies", Journal of Artificial Intelligence Review, 2004.
Chandola, V. and Banerjee, A. and Kumar, V. "Outlier detection: A survey", ACM Computing Surveys, 2007.
k-means对数据集中的噪声非常敏感。最好在进行聚类之前删除异常值。
不是这样的。任何声称是无参数的聚类分析算法通常都受到严格限制,并且往往有隐藏的参数 - 例如,距离函数就是一个常见的参数。任何灵活的聚类分析算法都至少接受自定义距离函数。
单类分类器是一种流行的机器学习方法,用于检测异常值。然而,监督方法并不总是适合于检测以前未见过的对象。此外,当数据已经包含异常值时,它们可能会出现过拟合。
每种方法都有其优缺点,这就是它们存在的原因。在实际情况下,您将不得不尝试大多数方法,以查看哪种方法适用于您的数据和设置。这就是为什么异常值检测被称为知识发现 - 如果您想要发现一些新的内容,就必须进行探索...
您可能想要查看ELKI数据挖掘框架。它被认为是最大的异常检测数据挖掘算法集合。它是开源软件,用Java实现,并包括20多个异常检测算法。请参阅可用算法列表。
请注意,这些算法中的大多数不是基于聚类的。许多聚类算法(特别是k-means)将尝试“无论如何”对实例进行聚类。只有少数聚类算法(例如DBSCAN)实际上考虑到可能并非所有实例都属于聚类的情况!因此,对于某些算法,异常值实际上会阻止良好的聚类!