四列数据的数据框:
x1 x2 x3 x4
期望的输出:
x1/x2 x1/x2 x1/x3 x2/x3 x2/x4 x3/x4
我希望创建新的列,这些列是原始列的比率。
我能想到的唯一方法就是手动完成:
df['x1/x2'] = df['x1']/df['x2']
然而,原始数据框中将有超过20列。 有什么方法可以自动化这个过程吗? 我在考虑使用for循环,但我不知道从哪里开始。感谢您的帮助。
创建所有列名称的配对组合,循环并分割到新列中:
from itertools import combinations
for a, b in combinations(df.columns, 2):
df[f'{a}/{b}'] = df[a].div(df[b])
concat连接在一起,并通过join添加原始列:df = df.join(pd.concat([df[a].div(df[b]).rename(f'{a}/{b}')
for a, b in combinations(df.columns, 2)], 1))
print (df)
x1 x2 x3 x4 x1/x2 x1/x3 x1/x4 x2/x3 x2/x4 x3/x4
0 4 7 1 5 0.571429 4.000000 0.800000 7.000000 1.400000 0.200000
1 5 8 3 3 0.625000 1.666667 1.666667 2.666667 2.666667 1.000000
2 4 9 5 6 0.444444 0.800000 0.666667 1.800000 1.500000 0.833333
3 5 4 7 9 1.250000 0.714286 0.555556 0.571429 0.444444 0.777778
4 5 2 1 2 2.500000 5.000000 2.500000 2.000000 1.000000 0.500000
5 4 3 0 4 1.333333 inf 1.000000 inf 0.750000 0.000000
你可以尝试:
df = pd.DataFrame({'x1':[1,2,3,4,5], 'x2': [10, 10, 10, 10, 10], 'x3' : [100, 100, 100 ,100, 100], 'x4': [10, 10, 10, 10, 10]})
columns = df.columns
def pattern(c = columns):
yield from ((v1, v2) for i, v1 in enumerate(c) for v2 in c[i + 1:])
for name1, name2 in pattern():
df[f'{name1}/{name2}'] = df[name1].div(df[name2])
输出:
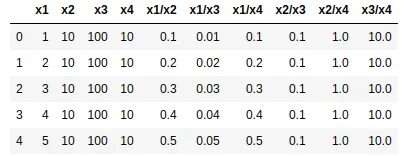
此外,您还可以将所有所需列连接起来:
pd.concat([df[n1].div(df[n2]).rename(f'{n1}/{n2}') for n1, n2 in pattern()], 1)
输出:
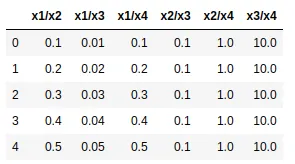
你可以使用赋值的一行代码:
import pandas as pd
from itertools import combinations
df = df.assign(**{f'{a}/{b}': df[a]/df[b] for a,b in combinations(df,2)})