Excel文件(扩展名为.xlsx)实际上是zip存档。 (您实际上可以使用7-zip或某些类似的程序打开Excel文件。)因此,Excel文件包含一堆xml文件,其中存储了数据。 Openpyxl所做的就是在打开Excel文件时从这些xml文件中读取数据,并在保存Excel文件时创建带有xml文件的zip存档。简单地说,openpyxl会读取一些xml文件,然后解析该数据,然后您可以使用openpyxl库中的函数来更改和添加数据,最后当您保存工作簿时,openpyxl将创建xml文件,将数据写入它们,并将它们保存为zip存档(即Excel文件)。这些XML文件包含存储在Excel文件中的所有数据(一个XML文件包含Excel文件中的公式,另一个将包含样式,在其他文件中将包含有关Excel主题的数据等)。我们只关心存储在两个XML文件中的Excel文件中的字符串:
正如您所看到的,您将失去所有单元格(字符串)的原始格式,并且您将获得某种合并格式的单元格(因此,如果单元格中的某些字符是粗体,而另一些字符不是,则保存文件时,整个单元格将是粗体或整个单元格将是普通)。现在人们要求开发人员实现这种富文本选项(link1,link2),但他们说这将很难实现。我同意这不容易做到,但我们可以做一些更简单的事情:当我们打开Excel文件时,我们可以从 sharedStrings.xml 中获取数据,然后在我们想要保存Excel文件时使用该xml代码,但仅适用于在我们打开文件时存在的单元格。这可能不容易理解,因此让我们看以下示例:
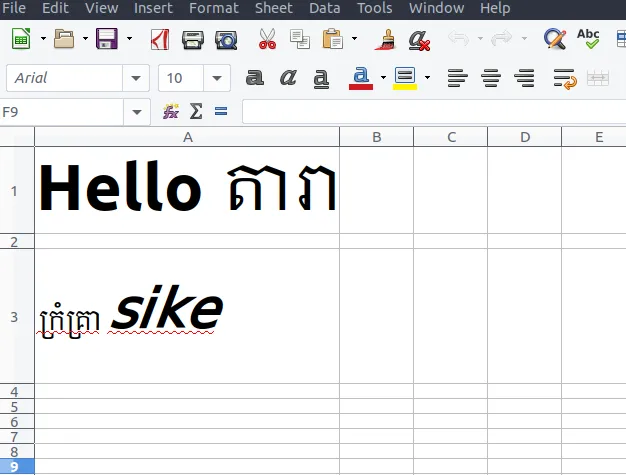
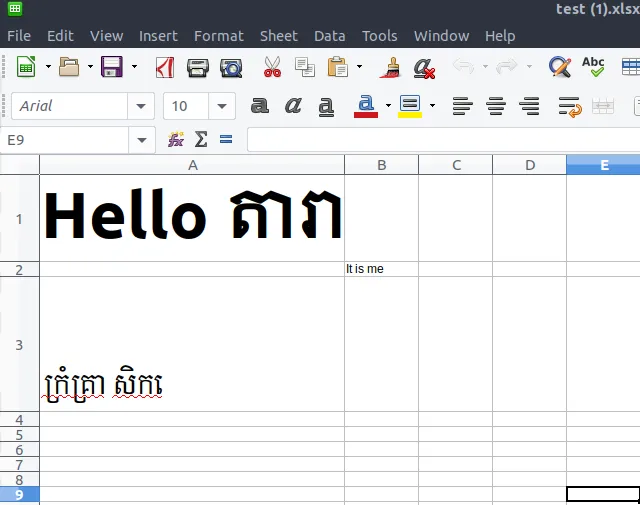
假设您有这样的Excel文件:
对于这个Excel文件,sharedStrings.xml将是这样的:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" count="1" uniqueCount="1">
<si>
<r>
<rPr>
<b/>
<sz val="22"/>
<color theme="1"/>
<rFont val="Calibri"/>
<family val="2"/>
<scheme val="minor"/>
</rPr>
<t>Hello</t>
</r>
<r>
<rPr>
<sz val="22"/>
<color theme="1"/>
<rFont val="Calibri"/>
<family val="2"/>
<scheme val="minor"/>
</rPr>
<t xml:space="preserve"> ត</t>
</r>
</si>
</sst>
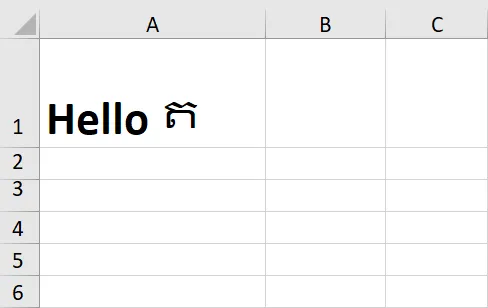
如果您运行以下Python代码:
from openpyxl import load_workbook
workbook = load_workbook(FILENAME1, keep_links=False)
sheet = workbook.active
sheet['A2'] = 'It is me'
workbook.save('out.xlsx')
文件 out.xlsx 的样子将会是这样:
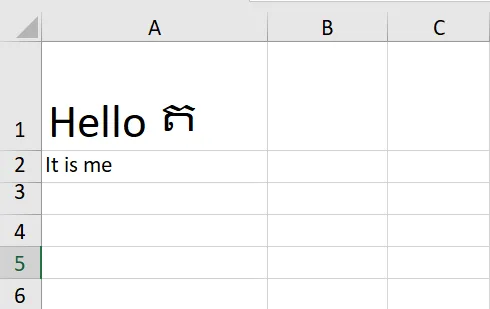
对于 out.xlsx 文件,其 sharedStrings.xml 将如下所示:
<sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" uniqueCount="2">
<si>
<t>Hello ត</t>
</si>
<si>
<t>It is me</t>
</si>
</sst>
所以我们想要做的是使用这段 XML 代码:
<si>
<r>
<rPr>
<b/>
<sz val="22"/>
<color theme="1"/>
<rFont val="Calibri"/>
<family val="2"/>
<scheme val="minor"/>
</rPr>
<t>Hello</t>
</r>
<r>
<rPr>
<sz val="22"/>
<color theme="1"/>
<rFont val="Calibri"/>
<family val="2"/>
<scheme val="minor"/>
</rPr>
<t xml:space="preserve"> ត</t>
</r>
</si>
对于包含Hello ត的旧单元格A1和以下XML代码:
<si>
<t>It is me</t>
</si>
对于包含It is me的新单元格A2。
因此,我们可以将这些XML部分组合起来,以获得如下所示的XML文件:
<sst xmlns="http:
<si>
<r>
<rPr>
<b/>
<sz val="22"/>
<color theme="1"/>
<rFont val="Calibri"/>
<family val="2"/>
<scheme val="minor"/>
</rPr>
<t>Hello</t>
</r>
<r>
<rPr>
<sz val="22"/>
<color theme="1"/>
<rFont val="Calibri"/>
<family val="2"/>
<scheme val="minor"/>
</rPr>
<t xml:space="preserve"> ត</t>
</r>
</si>
<si>
<t>It is me</t>
</si>
</sst>
我编写了一些函数来实现这个功能。 (代码很多,但大部分只是从openpyxl复制过来的。如果您更改了openpyxl库,您可以用10或20行代码完成此操作,但这永远不是一个好主意,所以我宁愿复制整个函数并更改需要更改的那个小部分。)
您可以将以下代码保存在单独的文件extendedopenpyxl.py中:
from openpyxl import load_workbook as openpyxlload_workbook
from openpyxl.reader.excel import _validate_archive, _find_workbook_part
from openpyxl.reader.worksheet import _get_xml_iter
from openpyxl.xml.functions import fromstring, iterparse, safe_iterator, tostring, Element, xmlfile, SubElement
from openpyxl.xml.constants import ARC_CONTENT_TYPES, SHEET_MAIN_NS, SHARED_STRINGS, ARC_ROOT_RELS, ARC_APP, ARC_CORE, ARC_THEME, ARC_SHARED_STRINGS, ARC_STYLE, ARC_WORKBOOK, ARC_WORKBOOK_RELS
from openpyxl.packaging.manifest import Manifest
from openpyxl.packaging.relationship import get_dependents, get_rels_path
from openpyxl.packaging.workbook import WorkbookParser
from openpyxl.packaging.extended import ExtendedProperties
from openpyxl.utils import coordinate_to_tuple
from openpyxl.cell.text import Text
from openpyxl.writer.excel import ExcelWriter as openpyxlExcelWriter
from openpyxl.writer.workbook import write_root_rels, write_workbook_rels, write_workbook
from openpyxl.writer.theme import write_theme
from openpyxl.writer.etree_worksheet import get_rows_to_write
from openpyxl.styles.stylesheet import write_stylesheet
from zipfile import ZipFile, ZIP_DEFLATED
from operator import itemgetter
from io import BytesIO
from xml.etree.ElementTree import tostring as xml_tostring
from xml.etree.ElementTree import register_namespace
from lxml.etree import fromstring as lxml_fromstring
register_namespace('', 'http://schemas.openxmlformats.org/spreadsheetml/2006/main')
def get_value_cells(workbook):
value_cells = []
for idx, worksheet in enumerate(workbook.worksheets, 1):
all_rows = get_rows_to_write(worksheet)
for row_idx, row in all_rows:
row = sorted(row, key=itemgetter(0))
for col, cell in row:
if cell._value is not None:
if cell.data_type == 's':
value_cells.append((worksheet.title,(cell.row, cell.col_idx)))
return value_cells
def check_if_lxml(element):
if type(element).__module__ == 'xml.etree.ElementTree':
string = xml_tostring(element)
el = lxml_fromstring(string)
return el
return element
def write_string_table(workbook):
string_table = workbook.shared_strings
workbook_data = workbook.new_interal_value_workbook_data
data_strings = workbook.new_interal_value_data_strings
value_cells = get_value_cells(workbook)
out = BytesIO()
i = 0
with xmlfile(out) as xf:
with xf.element("sst", xmlns=SHEET_MAIN_NS, uniqueCount="%d" % len(string_table)):
for i, key in enumerate(string_table):
sheetname, coordinates = value_cells[i]
if coordinates in workbook_data[sheetname]:
value = workbook_data[sheetname][coordinates]
xml_el = data_strings[value]
el = check_if_lxml(xml_el)
else:
el = Element('si')
text = SubElement(el, 't')
text.text = key
if key.strip() != key:
text.set(PRESERVE_SPACE, 'preserve')
xf.write(el)
return out.getvalue()
class ExcelWriter(openpyxlExcelWriter):
def write_data(self):
"""Write the various xml files into the zip archive."""
archive = self._archive
archive.writestr(ARC_ROOT_RELS, write_root_rels(self.workbook))
props = ExtendedProperties()
archive.writestr(ARC_APP, tostring(props.to_tree()))
archive.writestr(ARC_CORE, tostring(self.workbook.properties.to_tree()))
if self.workbook.loaded_theme:
archive.writestr(ARC_THEME, self.workbook.loaded_theme)
else:
archive.writestr(ARC_THEME, write_theme())
self._write_worksheets()
self._write_chartsheets()
self._write_images()
self._write_charts()
string_table_out = write_string_table(self.workbook)
self._archive.writestr(ARC_SHARED_STRINGS, string_table_out)
self._write_external_links()
stylesheet = write_stylesheet(self.workbook)
archive.writestr(ARC_STYLE, tostring(stylesheet))
archive.writestr(ARC_WORKBOOK, write_workbook(self.workbook))
archive.writestr(ARC_WORKBOOK_RELS, write_workbook_rels(self.workbook))
self._merge_vba()
self.manifest._write(archive, self.workbook)
return
def save(self, filename):
self.write_data()
self._archive.close()
return
def get_coordinates(cell, row_count, col_count):
coordinate = cell.get('r')
if coordinate:
row, column = coordinate_to_tuple(coordinate)
else:
row, column = row_count, col_count
return row, column
def parse_cell(cell):
VALUE_TAG = '{%s}v' % SHEET_MAIN_NS
value = cell.find(VALUE_TAG)
if value is not None:
value = int(value.text)
return value
def parse_row(row, row_count):
CELL_TAG = '{%s}c' % SHEET_MAIN_NS
if row.get('r'):
row_count = int(row.get('r'))
else:
row_count += 1
col_count = 0
data = dict()
for cell in safe_iterator(row, CELL_TAG):
col_count += 1
value = parse_cell(cell)
if value is not None:
coordinates = get_coordinates(cell, row_count, col_count)
data[coordinates] = value
return data
def parse_sheet(xml_source):
dispatcher = ['{%s}mergeCells' % SHEET_MAIN_NS, '{%s}col' % SHEET_MAIN_NS, '{%s}row' % SHEET_MAIN_NS, '{%s}conditionalFormatting' % SHEET_MAIN_NS, '{%s}legacyDrawing' % SHEET_MAIN_NS, '{%s}sheetProtection' % SHEET_MAIN_NS, '{%s}extLst' % SHEET_MAIN_NS, '{%s}hyperlink' % SHEET_MAIN_NS, '{%s}tableParts' % SHEET_MAIN_NS]
row_count = 0
stream = _get_xml_iter(xml_source)
it = iterparse(stream, tag=dispatcher)
row_tag = '{%s}row' % SHEET_MAIN_NS
data = dict()
for _, element in it:
tag_name = element.tag
if tag_name == row_tag:
row_data = parse_row(element, row_count)
data.update(row_data)
element.clear()
return data
def get_workbook_parser(archive):
src = archive.read(ARC_CONTENT_TYPES)
root = fromstring(src)
package = Manifest.from_tree(root)
wb_part = _find_workbook_part(package)
workbook_part_name = wb_part.PartName[1:]
parser = WorkbookParser(archive, workbook_part_name)
parser.parse()
return parser, package
def get_data_strings(xml_source):
STRING_TAG = '{%s}si' % SHEET_MAIN_NS
strings = []
src = _get_xml_iter(xml_source)
for _, node in iterparse(src):
if node.tag == STRING_TAG:
strings.append(node)
return strings
def load_workbook(filename, *args, **kwargs):
workbook = openpyxlload_workbook(filename, *args, **kwargs)
archive = _validate_archive(filename)
parser, package = get_workbook_parser(archive)
workbook_data = dict()
for sheet, rel in parser.find_sheets():
sheet_name = sheet.name
worksheet_path = rel.target
fh = archive.open(worksheet_path)
sheet_data = parse_sheet(fh)
workbook_data[sheet_name] = sheet_data
data_strings = []
ct = package.find(SHARED_STRINGS)
if ct is not None:
strings_path = ct.PartName[1:]
strings_source = archive.read(strings_path)
data_strings = get_data_strings(strings_source)
workbook.new_interal_value_workbook_data = workbook_data
workbook.new_interal_value_data_strings = data_strings
return workbook
def save_workbook(workbook, filename,):
archive = ZipFile(filename, 'w', ZIP_DEFLATED, allowZip64=True)
writer = ExcelWriter(workbook, archive)
writer.save(filename)
return True
def save_virtual_workbook(workbook,):
temp_buffer = BytesIO()
archive = ZipFile(temp_buffer, 'w', ZIP_DEFLATED, allowZip64=True)
writer = ExcelWriter(workbook, archive)
try:
writer.write_data()
finally:
archive.close()
virtual_workbook = temp_buffer.getvalue()
temp_buffer.close()
return virtual_workbook
现在,如果您运行此代码:
from extendedopenpyxl import load_workbook, save_workbook
workbook = load_workbook(FILENAME1, keep_links=False)
sheet = workbook['Sheet']
sheet['A2'] = 'It is me'
save_workbook(workbook, 'out.xlsx')
当我在上面例子中使用的Excel文件上运行这段代码时,我得到了以下结果:
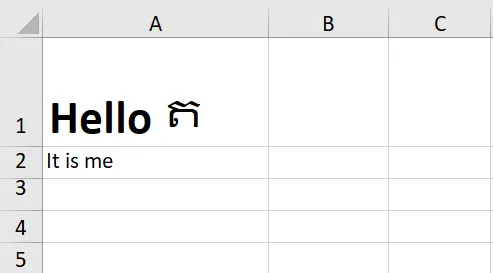
正如您所看到的,单元格A1中的文本格式与原来一样(Hello加粗,ត不加粗)。
编辑(West's comment之后)
如果您使用的是比2.5.14版本更高的openpyxl版本,则上面的代码将无法工作,因为openpyxl完全改变了它在excel文件中存储值的方式。
我已经修复了extendedopenpyxl.py中的部分代码,并且以下代码应该可以在新版本的openpyxl上工作(我在3.0.6版本上测试过):
from openpyxl.reader.excel import ExcelReader, _validate_archive
from openpyxl.xml.constants import SHEET_MAIN_NS, SHARED_STRINGS, ARC_SHARED_STRINGS, ARC_APP, ARC_CORE, ARC_THEME, ARC_STYLE, ARC_ROOT_RELS, ARC_WORKBOOK, ARC_WORKBOOK_RELS
from openpyxl.xml.functions import iterparse, xmlfile, tostring
from openpyxl.utils import coordinate_to_tuple
import openpyxl.cell._writer
from zipfile import ZipFile, ZIP_DEFLATED
from openpyxl.writer.excel import ExcelWriter
from io import BytesIO
from xml.etree.ElementTree import register_namespace
from xml.etree.ElementTree import tostring as xml_tostring
from lxml.etree import fromstring as lxml_fromstring
from openpyxl.worksheet._writer import WorksheetWriter
from openpyxl.workbook._writer import WorkbookWriter
from openpyxl.packaging.extended import ExtendedProperties
from openpyxl.styles.stylesheet import write_stylesheet
from openpyxl.packaging.relationship import Relationship
from openpyxl.cell._writer import write_cell
from openpyxl.drawing.spreadsheet_drawing import SpreadsheetDrawing
from openpyxl import LXML
from openpyxl.packaging.manifest import DEFAULT_OVERRIDE, Override, Manifest
DEFAULT_OVERRIDE.append(Override("/" + ARC_SHARED_STRINGS, SHARED_STRINGS))
def to_integer(value):
if type(value) == int:
return value
if type(value) == str:
try:
num = int(value)
return num
except ValueError:
num = float(value)
if num.is_integer():
return int(num)
raise ValueError('Value {} is not an integer.'.format(value))
return
def parse_cell(cell):
VALUE_TAG = '{%s}v' % SHEET_MAIN_NS
data_type = cell.get('t', 'n')
value = None
if data_type == 's':
value = cell.findtext(VALUE_TAG, None) or None
if value is not None:
value = int(value)
return value
def get_coordinates(cell, row_counter, col_counter):
coordinate = cell.get('r')
if coordinate:
row, column = coordinate_to_tuple(coordinate)
else:
row, column = row_counter, col_counter
return row, column
def parse_row(row, row_counter):
row_counter = to_integer(row.get('r', row_counter + 1))
col_counter = 0
data = dict()
for cell in row:
col_counter += 1
value = parse_cell(cell)
if value is not None:
coordinates = get_coordinates(cell, row_counter, col_counter)
data[coordinates] = value
col_counter = coordinates[1]
return data, row_counter
def parse_sheet(xml_source):
ROW_TAG = '{%s}row' % SHEET_MAIN_NS
row_counter = 0
it = iterparse(xml_source)
data = dict()
for _, element in it:
tag_name = element.tag
if tag_name == ROW_TAG:
pass
row_data, row_counter = parse_row(element, row_counter)
data.update(row_data)
element.clear()
return data
def extended_archive_open(archive, name):
with archive.open(name,) as src:
namespaces = {node[0]: node[1] for _, node in
iterparse(src, events=['start-ns'])}
for key, value in namespaces.items():
register_namespace(key, value)
return archive.open(name,)
def get_data_strings(xml_source):
STRING_TAG = '{%s}si' % SHEET_MAIN_NS
strings = []
for _, node in iterparse(xml_source):
if node.tag == STRING_TAG:
strings.append(node)
return strings
def load_workbook(filename, read_only=False, keep_vba=False,
data_only=False, keep_links=True):
reader = ExcelReader(filename, read_only, keep_vba,
data_only, keep_links)
reader.read()
archive = _validate_archive(filename)
workbook_data = dict()
for sheet, rel in reader.parser.find_sheets():
if rel.target not in reader.valid_files or "chartsheet" in rel.Type:
continue
fh = archive.open(rel.target)
sheet_data = parse_sheet(fh)
workbook_data[sheet.name] = sheet_data
data_strings = []
ct = reader.package.find(SHARED_STRINGS)
if ct is not None:
strings_path = ct.PartName[1:]
with extended_archive_open(archive, strings_path) as src:
data_strings = get_data_strings(src)
archive.close()
workbook = reader.wb
workbook._extended_value_workbook_data = workbook_data
workbook._extended_value_data_strings = data_strings
return workbook
def check_if_lxml(element):
if type(element).__module__ == 'xml.etree.ElementTree':
string = xml_tostring(element)
el = lxml_fromstring(string)
return el
return element
def write_string_table(workbook):
workbook_data = workbook._extended_value_workbook_data
data_strings = workbook._extended_value_data_strings
out = BytesIO()
with xmlfile(out) as xf:
with xf.element("sst", xmlns=SHEET_MAIN_NS, uniqueCount="%d" % len(data_strings)):
for sheet in workbook_data:
for coordinates, value in workbook_data[sheet].items():
xml_el = data_strings[value]
el = check_if_lxml(xml_el)
xf.write(el)
return out.getvalue()
def check_cell(cell):
if cell.data_type != 's':
return False
if cell._comment is not None:
return False
if cell.hyperlink:
return False
return True
def extended_write_cell(xf, worksheet, cell, styled=None):
workbook_data = worksheet.parent._extended_value_workbook_data
for sheet in workbook_data.values():
if (cell.row, cell.column) in sheet and check_cell(cell):
attributes = {'r': cell.coordinate, 't': cell.data_type}
if styled:
attributes['s'] = '%d' % cell.style_id
if LXML:
with xf.element('c', attributes):
with xf.element('v'):
xf.write('%.16g' % sheet[(cell.row, cell.column)])
else:
el = Element('c', attributes)
cell_content = SubElement(el, 'v')
cell_content.text = '%.16g' % sheet[(cell.row, cell.column)]
xf.write(el)
break
else:
write_cell(xf, worksheet, cell, styled)
return
class ExtendedWorksheetWriter(WorksheetWriter):
def write_row(self, xf, row, row_idx):
attrs = {'r': f"{row_idx}"}
dims = self.ws.row_dimensions
attrs.update(dims.get(row_idx, {}))
with xf.element("row", attrs):
for cell in row:
if cell._comment is not None:
comment = CommentRecord.from_cell(cell)
self.ws._comments.append(comment)
if (
cell._value is None
and not cell.has_style
and not cell._comment
):
continue
extended_write_cell(xf, self.ws, cell, cell.has_style)
return
class ExtendedWorkbookWriter(WorkbookWriter):
def write_rels(self, *args, **kwargs):
styles = Relationship(type='sharedStrings', Target='sharedStrings.xml')
self.rels.append(styles)
return super().write_rels(*args, **kwargs)
class ExtendedExcelWriter(ExcelWriter):
def __init__(self, workbook, archive):
self._archive = archive
self.workbook = workbook
self.manifest = Manifest(Override = DEFAULT_OVERRIDE)
self.vba_modified = set()
self._tables = []
self._charts = []
self._images = []
self._drawings = []
self._comments = []
self._pivots = []
return
def write_data(self):
archive = self._archive
props = ExtendedProperties()
archive.writestr(ARC_APP, tostring(props.to_tree()))
archive.writestr(ARC_CORE, tostring(self.workbook.properties.to_tree()))
if self.workbook.loaded_theme:
archive.writestr(ARC_THEME, self.workbook.loaded_theme)
else:
archive.writestr(ARC_THEME, theme_xml)
self._write_worksheets()
self._write_chartsheets()
self._write_images()
self._write_charts()
if self.workbook._extended_value_workbook_data \
and self.workbook._extended_value_data_strings:
string_table_out = write_string_table(self.workbook)
self._archive.writestr(ARC_SHARED_STRINGS, string_table_out)
self._write_external_links()
stylesheet = write_stylesheet(self.workbook)
archive.writestr(ARC_STYLE, tostring(stylesheet))
writer = ExtendedWorkbookWriter(self.workbook)
archive.writestr(ARC_ROOT_RELS, writer.write_root_rels())
archive.writestr(ARC_WORKBOOK, writer.write())
archive.writestr(ARC_WORKBOOK_RELS, writer.write_rels())
self._merge_vba()
self.manifest._write(archive, self.workbook)
return
def write_worksheet(self, ws):
ws._drawing = SpreadsheetDrawing()
ws._drawing.charts = ws._charts
ws._drawing.images = ws._images
if self.workbook.write_only:
if not ws.closed:
ws.close()
writer = ws._writer
else:
writer = ExtendedWorksheetWriter(ws)
writer.write()
ws._rels = writer._rels
self._archive.write(writer.out, ws.path[1:])
self.manifest.append(ws)
writer.cleanup()
return
def save_workbook(workbook, filename):
archive = ZipFile(filename, 'w', ZIP_DEFLATED, allowZip64=True)
writer = ExtendedExcelWriter(workbook, archive)
writer.save()
return True
 。
。