虽然我一直在寻找,但我无法找到在pandas中实现此查询的正确方法。
update product
set maxrating = (select max(rating)
from rating
where source = 'customer'
and product.sku = rating.sku
group by sku)
where maxrating is null;
Pandas
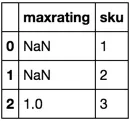
product = pd.DataFrame({'sku':[1,2,3],'maxrating':[0,0,1]})
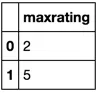
rating = pd.DataFrame({'sku':[1,1,2,3,3],'rating':[2,5,3,5,4],'source':['retailer','customer','customer','retailer','customer']})
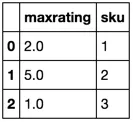
expected_result = pd.DataFrame({'sku':[1,2,3],'maxrating':[5,3,1]})
SQL
drop table if exists product;
create table product(sku integer primary key, maxrating int);
insert into product(maxrating) values(null),(null),(1);
drop table if exists rating; create table rating(sku int, rating int, source text);
insert into rating values(1,2,'retailer'),(1,5,'customer'),(2,3,'customer'),(2,5,'retailer'),(3,3,'retailer'),(3,4,'customer');
update product
set maxrating = (select max(rating)
from rating
where source = 'customer'
and product.sku = rating.sku
group by sku)
where maxrating is null;
select *
from product;
如何完成?