有人能用简单明了的英语或易于理解的方式向我解释吗?
9个回答
77
归并排序使用“分而治之”的方法来解决排序问题。首先,使用递归将输入分成两半。分割后,对其进行排序并将它们合并成一个已排序的输出。见下图:
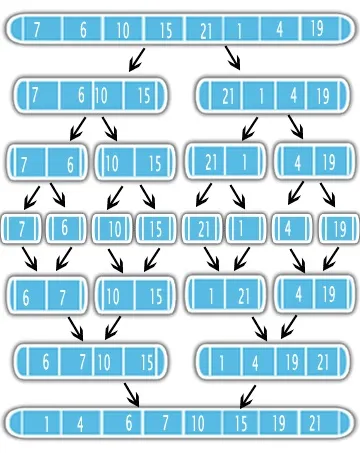
这意味着最好先排序一半的问题,然后再执行一个简单的合并子程序。因此,了解合并子程序的复杂度以及在递归中调用的次数非常重要。
归并排序的伪代码非常简单。
# C = output [length = N]
# A 1st sorted half [N/2]
# B 2nd sorted half [N/2]
i = j = 1
for k = 1 to n
if A[i] < B[j]
C[k] = A[i]
i++
else
C[k] = B[j]
j++
很容易看出,在每次循环中您将有4个操作:k++,i++或j++,if语句和赋值C = A | B。因此,您将拥有不超过4N + 2个操作,从而得到O(N)的复杂度。为了证明,将4N + 2视为6N,因为对于N = 1(4N + 2 <= 6N),这是成立的。
因此,假设您有一个输入具有N个元素,并且假设N是2的幂。在每个级别上,您会有两倍于前一个输入的一半元素的子问题。这意味着在级别j = 0,1,2,...,lgN处,将有个子问题,其输入长度为N / 2^j。在每个级别j处的操作次数将小于或等于
= 6N
请注意,无论哪个级别,您始终不会超过6N次操作。
由于有lgN + 1个级别,因此复杂度将为
O(6N *(lgN + 1))= O(6N*lgN + 6N)= O(n lgN)
参考资料:
- Davi Sampaio
3
1为什么第一个
n 是小写,而第二个 N 是大写?这有什么意义吗? - Pacerier1也许我做得不好,但是
2^j * 6(N / 2^j) = 6N还需要进行两个操作。
虽然这些操作并不重要,但在这种情况下,它应该是这样的:
2^j * 6(N / 2^j) + 2 = 6N
正如你所说,将会有不超过6N次操作。 - Jorman Bustos讲解得非常清楚明了 - undefined
45
在传统的归并排序中,每次对数据进行排序时都会将已排序的子段长度加倍。第一次排序后,文件将被排序成长度为两个记录的小节,第二遍排序后是长度为四个记录的小节,然后是八个、十六个等,一直到整个文件的大小。
必须不断地将已排序的子段长度加倍,直到只剩下一个包含整个文件的子段。需要lg(N)次对子段大小进行加倍才能达到文件大小,并且每次对数据进行排序的时间都与记录数成比例。
- supercat
5
25这是一个很好的答案,但我不得不读几遍才懂。举个例子可能会有帮助...例如,假设你有一个包含8个数字的列表。将它们拆分成长度为1的子列表。要将列表长度加倍到8,需要进行3次加倍或lg(8)次操作。在最坏的情况下,您必须逐个检查每个子列表中的每个成员,这意味着在进行所有三次加倍时,您都必须检查所有8个值。 - Goodword
我刚刚添加了这样一个例子,你喜欢这个更好吗? - supercat
在这种情况下,它不应该是log2N吗?就像回答有多少次2被乘以2得到N一样。所以我们得到2、4、8、16。哇,它是3次。 - xpioneer
@xpioneer:如果一个操作需要时间O(f(N))才能完成,那么就意味着存在一些常数n'和k,使得对于所有的N >= n',时间都会小于k f(n)。由于以2为底的N的对数是自然对数的一个常数倍,因此O(Nlg(N))和O(Nln(N))是等价的。 - supercat
@supercat。明白了。在其他地方找不到更好的解释了。 - xpioneer
33
将数组分割到只剩单个元素为止,即生成子列表。
在每个阶段,我们将每个子列表的元素与其相邻子列表的元素进行比较。例如,[重用@Davi的图像]
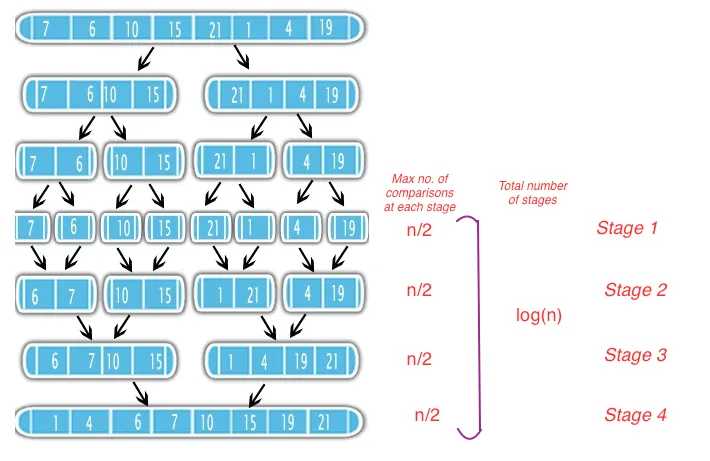
- 在第1阶段,每个元素都会与其相邻元素进行比较,因此进行了n / 2次比较。
- 在第2阶段,将每个子列表的元素与其相邻的子列表的元素进行比较,由于每个子列表都已排序,这意味着两个子列表之间进行的最大比较次数<=子列表的长度,即2(在第2阶段),第3阶段进行4次比较,第4阶段进行8次比较,因为子列表的长度不断加倍。这意味着每个阶段的最大比较次数=(子列表的长度*(子列表数量/ 2))==> n/2
- 正如您所观察到的,总阶段数将是
log(n) base 2因此,总复杂度为 == (每个阶段的最大比较次数*阶段数) == O((n/2)*log(n)) ==> O(nlog(n))
- Chenna V
29
算法归并排序能够在O(n log n)的时间内对大小为n的序列S进行排序,假设S中的任意两个元素可以在O(1)的时间内进行比较。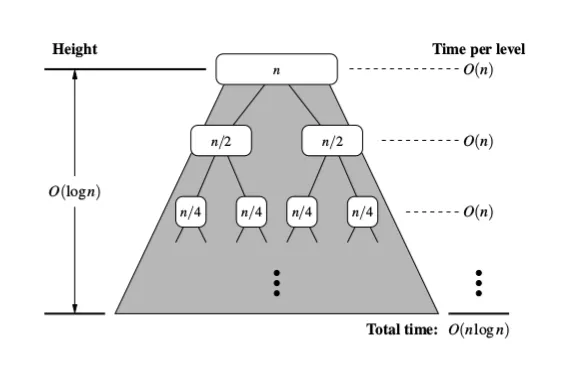
- Andrii Glukhyi
24
这是因为无论是最坏情况还是平均情况,归并排序在每个阶段只是将数组分成两半,这使得它具有lg(n)的复杂度。另外一个N的复杂度来自于每个阶段进行的比较。因此结合起来就近似于O(nlgn)。无论最坏情况还是平均情况,lg(n)这个因子总是存在的。其余的N因子取决于所做的比较,在两种情况下完成。现在最坏情况是当每一阶段对N个输入进行N次比较时发生的。这样就变成了O(nlgn)。
- Pankaj Anand
8
许多其他答案都很好,但我没有看到任何与“归并排序树”示例相关的“高度”和“深度”的提及。以下是另一种方法来解决这个问题,并且对树进行了重点关注。以下是另一张图片,以帮助解释: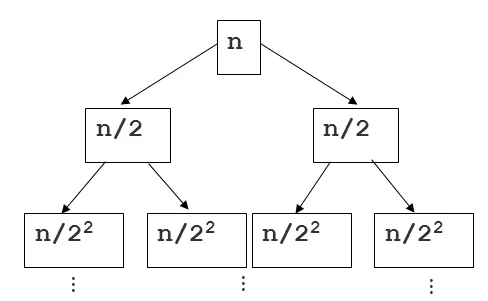 简单概括一下:正如其他答案所指出的那样,我们知道合并序列的两个已排序切片的工作以线性时间运行(从主排序函数调用的合并帮助函数)。现在查看这棵树,我们可以将根节点的每个后代(除根节点外)视为对排序函数的递归调用,让我们尝试评估每个节点花费多少时间…由于序列的分片和合并(两者结合)需要线性时间,因此任何节点的运行时间与该节点上的序列长度成线性关系。
简单概括一下:正如其他答案所指出的那样,我们知道合并序列的两个已排序切片的工作以线性时间运行(从主排序函数调用的合并帮助函数)。现在查看这棵树,我们可以将根节点的每个后代(除根节点外)视为对排序函数的递归调用,让我们尝试评估每个节点花费多少时间…由于序列的分片和合并(两者结合)需要线性时间,因此任何节点的运行时间与该节点上的序列长度成线性关系。
这就是树深度的作用。如果n是原始序列的总大小,则任何节点处的序列大小为n/2i,其中i是深度。这在上面的图像中显示。将这与每个切片的线性工作量结合起来,我们得到每个节点的运行时间为O(n/2i)。现在我们只需要对n个节点进行总合并。一种方法是认识到树的每个深度层上都有2i个节点。因此,对于任何水平,我们都有O(2i * n/2i),这是O(n),因为我们可以取消2i!如果每个深度都是O(n),我们只需将其乘以此二叉树的高度,即logn。答案:O(nlogn)
参考资料:Python中的数据结构和算法
简单概括一下:正如其他答案所指出的那样,我们知道合并序列的两个已排序切片的工作以线性时间运行(从主排序函数调用的合并帮助函数)。现在查看这棵树,我们可以将根节点的每个后代(除根节点外)视为对排序函数的递归调用,让我们尝试评估每个节点花费多少时间…由于序列的分片和合并(两者结合)需要线性时间,因此任何节点的运行时间与该节点上的序列长度成线性关系。这就是树深度的作用。如果n是原始序列的总大小,则任何节点处的序列大小为n/2i,其中i是深度。这在上面的图像中显示。将这与每个切片的线性工作量结合起来,我们得到每个节点的运行时间为O(n/2i)。现在我们只需要对n个节点进行总合并。一种方法是认识到树的每个深度层上都有2i个节点。因此,对于任何水平,我们都有O(2i * n/2i),这是O(n),因为我们可以取消2i!如果每个深度都是O(n),我们只需将其乘以此二叉树的高度,即logn。答案:O(nlogn)
参考资料:Python中的数据结构和算法
- trad
1
为了更清晰地表达和提供额外的上下文,当他说:“这个二叉树的高度是logn”时,这是因为(正如他所指出的),给定深度的节点总数为2 ^ i - 其中i从0开始。本质上:2 ^ i = 节点数(N)
// 双方取以2为底的对数
log(2 ^ i)= logN;
i * log2 = logN;
// log 2 = 1,因为2 ^ 1 = 2;
因此:
i = 树的高度= logN - bourgeois2475
递归树的深度为log(N),在每个层级上,你需要合并两个排序数组。每个层级中,你需要完成N次操作来执行这个合并操作。
合并排序数组:
要合并两个已排序的数组A[1,5]和B[3,4],只需从开头开始迭代两个数组,在两个数组之间选择最小元素并递增该数组的指针,当两个指针都到达各自的数组末尾时合并完成。
合并排序数组:
要合并两个已排序的数组A[1,5]和B[3,4],只需从开头开始迭代两个数组,在两个数组之间选择最小元素并递增该数组的指针,当两个指针都到达各自的数组末尾时合并完成。
[1,5] [3,4] --> []
^ ^
[1,5] [3,4] --> [1]
^ ^
[1,5] [3,4] --> [1,3]
^ ^
[1,5] [3,4] --> [1,3,4]
^ x
[1,5] [3,4] --> [1,3,4,5]
x x
Runtime = O(A + B)
归并排序示例
你的递归调用栈将会是这样的。工作从底部叶子节点开始,并向上冒泡。
beginning with [1,5,3,4], N = 4, depth k = log(4) = 2
[1,5] [3,4] depth = k-1 (2^1 nodes) * (N/2^1 values to merge per node) == N
[1] [5] [3] [4] depth = k (2^2 nodes) * (N/2^2 values to merge per node) == N
因此,您在树的每个k层上都要执行N个工作,其中k = log(N)
N * k = N * log(N)
- geg
2
那种排序算法有特定的名称吗?我指的是你解释过的那个排序算法,它需要 O(A + B) 的时间。 - Backrub32
@Poream3387 我不知道官方名称,但该算法用于“合并已排序的列表”。 - geg
4
MergeSort算法包含三个步骤:
- 划分 步骤计算子数组的中间位置,其时间复杂度为常数O(1)。
- 征服 步骤递归地对两个大小约为n/2的子数组进行排序。
- 合并 步骤在每次通过时合并总共n个元素,最多需要n次比较,因此其时间复杂度为O(n)。
- MisterJoyson
0
让我们以8个元素{1,2,3,4,5,6,7,8}为例,您首先必须将其分成两半,即n/2=4({1,2,3,4} {5,6,7,8}),这两个分割部分各需要0(n/2)和0(n/2)次,因此在第一步中,它需要0(n/2+n/2)=0(n)的时间。 2.下一步是将n/22分成(({1,2}{3,4})({5,6}{7,8})),分别需要(0(n/4),0(n/4),0(n/4),0(n/4)),这意味着这一步需要总共0(n/4+n/4+n/4+n/4)=0(n)的时间。 3.接下来与上一步类似,我们必须进一步将第二步除以2,即n/222 ((({1},{2},{3},{4})({5},{6},{7},{8})),其时间为0(n/8+n/8+n/8+n/8+n/8+n/8+n/8+n/8)=0(n),这意味着每个步骤都需要0(n)的时间。假设步骤为a,则归并排序所需的时间为0(an),这意味着a必须是log(n),因为步骤始终会被2除。因此,归并排序的TC最终为0(nlog(n))。
- Khushi Arora
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接