乍一看,归并排序的空间复杂度为O(n)是有道理的,因为为了对未排序的数组进行排序,我正在拆分和创建子数组,但所有子数组大小的总和将为n。
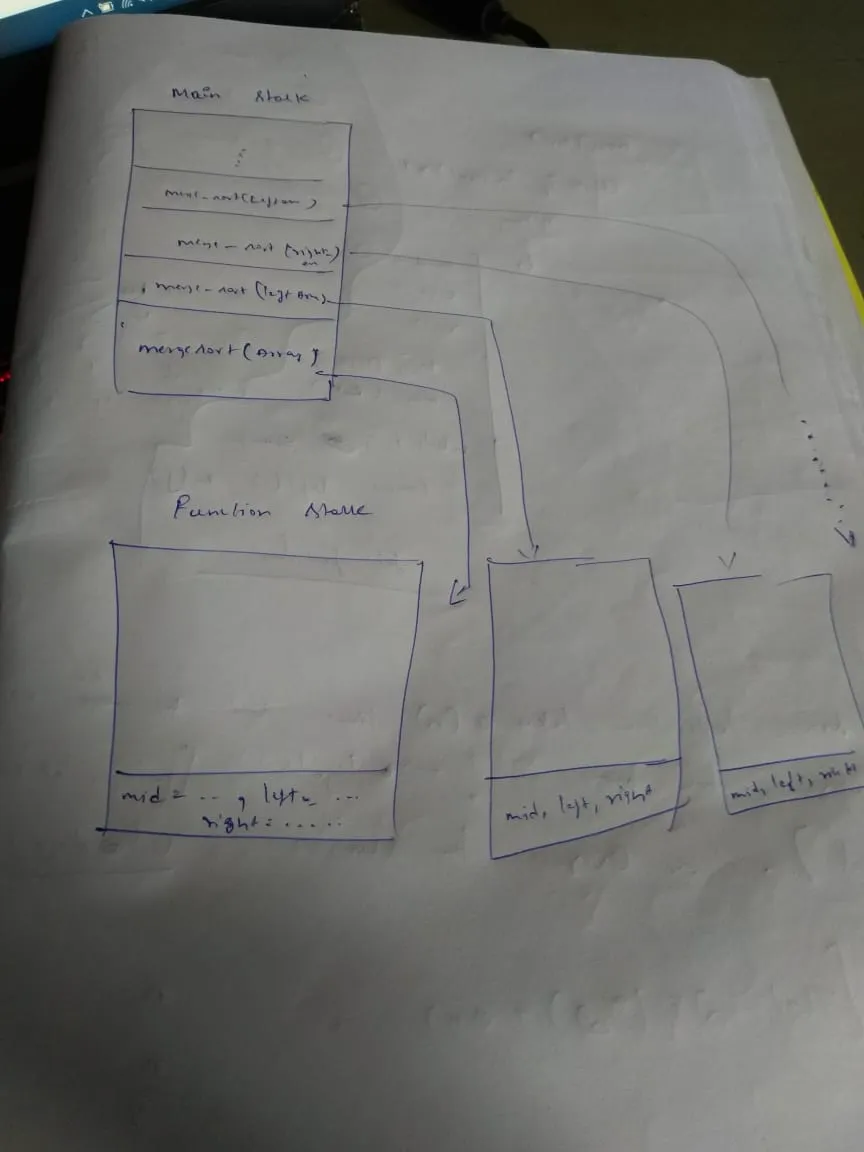
问题:我主要关心的是在递归期间mergerSort()函数的内存分配。我有一个主堆栈,并且每个对mergerSort()的函数调用(递归)都将被推送到堆栈上。现在,每次递归调用mergeSort()函数都会有自己的堆栈。因此,假设我们已经对mergeSort()进行了5次递归调用,则主堆栈将包含5个函数调用,其中每个函数调用都有自己的函数堆栈。现在,每个函数堆栈都将具有其自己的局部变量,例如函数创建的左子数组和右子数组。因此,这5个函数堆栈中的每一个都应该在内存中具有5个不同的子数组。因此,随着递归调用的增加,空间是否会增长?