我知道两个操作都是在表中对列执行的,但是每个操作有什么不同。
9个回答
278
数据分区常用于水平负载均衡,具有性能优势,并有助于以逻辑方式组织数据。例如:如果我们处理一个大的
employee表格,并且经常运行带有WHERE子句的查询将结果限制在特定的国家或部门。为了更快的查询响应,Hive表可以通过 PARTITIONED BY (country STRING, DEPT STRING) 进行分区。对表进行分区会改变Hive的数据存储结构,Hive现在会创建反映分区结构的子目录,如:
.../employees/country=ABC/DEPT=XYZ。
如果查询限制为从country=ABC的员工,则仅会扫描一个目录country=ABC 的内容。这可以极大地提高查询性能,但前提是分区方案反映出常见的筛选方式。分区功能在Hive中非常有用,但是,创建太多的分区的设计可能会优化一些查询,但对其他重要查询却有害无益。另一个缺点是如果拥有太多的分区,将会创建大量的Hadoop文件和不必要的目录,对NameNode造成额外的负担,因为它必须将文件系统的所有元数据保存在内存中。
分桶技术是将数据集分解为更易处理的部分的另一种技术。例如,假设一个表使用日期作为顶级分区,以员工ID作为第二级分区会导致太多的小分区。相反,如果我们对员工表进行分桶,并使用员工ID作为分桶列,该列的值将被用户定义的数字散列到桶中。具有相同员工ID的记录始终存储在同一个桶中。假设员工ID的数量远大于桶的数量,则每个桶将有许多员工ID。创建表时,您可以指定类似于CLUSTERED BY (employee_id) INTO XX BUCKETS; 的语句,其中XX是桶的数量。分桶具有几个优点。桶的数量是固定的,因此不会随数据波动。 如果两个表都按员工ID进行了分桶,则Hive可以创建逻辑上正确的抽样。分桶还有助于进行高效的映射端连接等操作。
- Navneet Kumar
8
7谢谢Navneet。但是,你能否详细说明如何通过分区进行桶操作?假设我们在 CLUSED BY 子句中指定了 32 个桶,并且 CREATE TABLE 语句也包含 Partitioning 子句,那么如何同时管理分区和桶?每个分区的数量是否将限制为 32?还是为每个分区创建 32 个桶?每个桶都是一个 HDFS 文件吗? - sgsi
16Hive表可以同时具有分区和桶的功能。根据您的分区语句,每个分区将创建32个bucket。是的,指的是HDFS文件。 - Navneet Kumar
12分区是一个文件夹,而存储桶则是一个文件。 - leftjoin
13记录一下,这个答案源自于《Hive 编程》(O'Reilly, 2012)一书的文本。 - ianmcook
1我发现这个链接很有用。它包含的信息将为这个答案增添更多价值。https://www.linkedin.com/pulse/hive-partitioning-bucketing-examples-gaurav-singh - Alex Raj Kaliamoorthy
显示剩余3条评论
151
前面的说明中缺少一些细节。为了更好地理解分区和桶的工作原理,您应该查看Hive中数据是如何存储的。 假设您有一个表。
CREATE TABLE mytable (
name string,
city string,
employee_id int )
PARTITIONED BY (year STRING, month STRING, day STRING)
CLUSTERED BY (employee_id) INTO 256 BUCKETS
那么Hive将以类似的目录层次结构存储数据
/user/hive/warehouse/mytable/y=2015/m=12/d=02
术语“基数”是指字段可能具有的可能值的数量。例如,如果您有一个“国家”字段,世界各地的国家大约有300个,因此基数将为〜300。对于像“timestamp_ms”这样每毫秒更改一次的字段,基数可以达到数十亿。一般而言,在选择用于分区的字段时,它不应具有很高的基数,因为您最终会在文件系统中拥有太多目录。
另一方面,聚类(也称为桶)将导致固定数量的文件,因为您确实指定了存储桶的数量。Hive会采取字段,计算哈希值并将记录分配给该桶。但是,如果您使用256个桶,并且您正在对其进行分桶的字段具有较低的基数(例如,它是美国州名,因此只能有50个不同的值)?您将拥有50个带有数据的桶和206个不带数据的桶。
有人已经提到过分区如何显着减少所查询的数据量。因此,在我的示例表中,如果您只想查询从某个日期开始的数据,则按年/月/日分区将显着减少IO量。
我想有人也提到过如何加速与其他表的联接(具有完全相同的分桶),因此在我的示例中,如果您正在连接两个表并且它们具有相同的employee_id,则Hive可以对每个存储桶进行连接(如果它们已经按employee_id排序,那么这将合并已经排序的部分,在线性时间内工作即O(n))。
因此,当字段具有较高的基数且数据均匀分布在存储桶中时,分桶效果很好。当分区字段的基数不太高时,分区效果最佳。
此外,您可以按顺序(年/月/日是一个很好的例子)在多个字段上进行分区,而只能在一个字段上进行分桶。
- Roberto Congiu
9
请问您能否举个例子解释一下 CLUSTERED-BY 和 SORTED-BY 的行为?根据我的例子,我发现 SORTED-BY 没有起到任何作用。我有什么遗漏吗? - Jagadish Talluri
2CLUSTERED BY x,y 就像编写 DISTRIBUTE BY x,y SORT BY x,y 一样(请参见 https://cwiki.apache.org/confluence/display/Hive/LanguageManual+SortBy#LanguageManualSortBy-SyntaxofClusterByandDistributeBy),因此在 CLUSTERED BY 中添加 SORT BY 是没有效果的。 - Roberto Congiu
我不确定你所说的“您只能在一个字段上进行分桶”的意思。我认为可以通过多个字段进行分桶,哈希函数只需将所有字段组合即可。 - Istvan
"线性时间运行的归并排序..." 这里我认为你只是指合并,而不是归并排序,因为归并排序的时间复杂度始终为O(n*log(n))。 - MaxNevermind
不是总是这样的......如果要合并的部分已经像我提到的例子一样排序好了,它可以在线性时间内工作。但是很好,我会添加一个澄清。 - Roberto Congiu
显示剩余4条评论
25
在涉及到分桶(Bucketing)之前,我们需要了解什么是分区(Partitioning)。让我们以下面的表格为例进行说明。请注意,我在下面的示例中仅提供了12条记录,以方便初学者理解。在实时情况下,您可能会有数百万条记录。
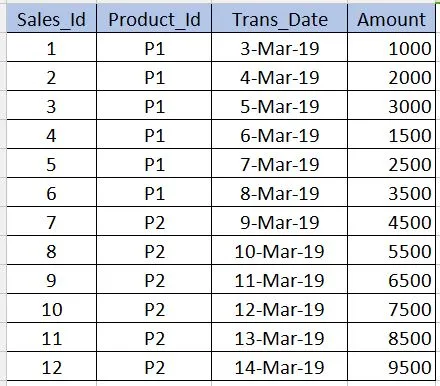
分区
---------------------
分区用于在查询数据时获得性能优化。例如,在上面的表格中,如果我们编写以下SQL,则需要扫描表中的所有记录,这会降低性能并增加开销。
select * from sales_table where product_id='P1'
为了避免全表扫描,只读取与product_id='P1'相关的记录,我们可以根据product_id列将Hive表的文件进行分区(拆分)。这样,Hive表的文件将被拆分成两个文件,一个包含product_id='P1',另一个包含product_id='P2'。现在,当我们执行上述查询时,它只会扫描product_id='P1'文件。
../hive/warehouse/sales_table/product_id=P1
../hive/warehouse/sales_table/product_id=P2
创建分区的语法如下。注意,在下面的语法中,我们不应该使用product_id列定义和非分区列一起使用。它应该仅在partitioned by子句中使用。
create table sales_table(sales_id int,trans_date date, amount int)
partitioned by (product_id varchar(10))
缺点:我们在进行分区时应该非常小心。也就是说,不应该用于重复值很少的列(特别是主键列),因为这会增加分区文件的数量并增加Name node的开销。
桶分区
------------------
桶分区(Bucketing)用于克服我在分区部分提到的缺点。当一列中有非常少量的重复值(例如主键列)时,应使用此方法。这类似于RDBMS中主键列上的索引概念。在我们的表中,可以使用Sales_Id列进行桶分区。当我们需要查询sales_id列时,它将非常有用。
下面是桶分区的语法。
create table sales_table(sales_id int,trans_date date, amount int)
partitioned by (product_id varchar(10)) Clustered by(Sales_Id) into 3 buckets
在这里,我们将数据根据分区进一步拆分成更多的文件。
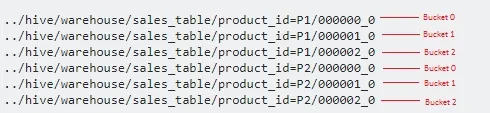
由于我们指定了3个桶,因此每个product_id会被拆分成3个文件。它内部使用取模运算符来确定每个sales_id应存储在哪个桶中。例如,对于product_id='P1',sales_id=1将被存储在000001_0文件中(即1%3=1),sales_id=2将被存储在000002_0文件中(即2%3=2),sales_id=3将被存储在000000_0文件中(即3%3=0)等。
- Sarath Subramanian
2
对于数值类型的聚集列,它是否总是通过桶的数量取模?对于字符串类型的聚集列,它是否使用字符串的Java
hashCode()作为哈希函数?程序员能否选择哈希函数? - Don Smith显然(根据我的实验),Hive使用了Java的hashCode()方法的变体:https://github.com/apache/hive/blob/release-1.1.0/serde/src/java/org/apache/hadoop/hive/serde2/objectinspector/ObjectInspectorUtils.java#L521-L531。这在这里提到过:https://stackoverflow.com/questions/30594038/how-hashing-works-in-bucketing-for-hive。 - Don Smith
19
我认为我回答这个问题有些晚了,但它一直出现在我的订阅中。
Navneet给出了很好的答案。从视觉上添加一些内容。
如果在WHERE子句中使用,分区可以帮助消除数据,而桶可以帮助将每个分区中的数据组织成多个文件,以便相同的数据集始终写入同一桶中。在列连接中非常有帮助。
假设您有一个具有五个列的表,名称为name,server_date,some_col3,some_col4和some_col5。假设您已经对server_date进行了分区,并在10个桶上对name列进行了划分,那么您的文件结构将如下所示。
- server_date=xyz
- 00000_0
- 00001_0
- 00002_0
- ........
- 00010_0
这里的server_date=xyz是分区,000文件是每个分区中的桶。桶是基于某些哈希函数计算的,因此具有name=Sandy的行将始终进入同一个桶中。
- Priyesh
2
2根据上面的回答,Roberto认为server_date不适合用于分区,因为它的基数值非常高。因此,在HDFS中会有太多的文件夹。 - Gaurang Shah
1这里以 server_date 为例进行说明。在现实世界中,分区通常会像 Roberto 所描述的那样,将日期分解为年/月/日。这就是正确的做法。 - Priyesh
18
- Ravindra babu
4
区别在于桶分配(bucketing)是按列名将文件划分,而分区(partitioning)是按表中特定值将文件划分。
希望我定义得正确。
- uriya harel
2
这里有很好的回答。我想简短地概括一下分区和桶之间的区别。
通常,您会在较不唯一的列上进行分区,而在最唯一的列上进行桶操作。
例如,如果您考虑世界人口中的国家、个人姓名和他们的生物识别ID作为示例。正如您所猜测的那样,国家字段将是较不唯一的列,而生物识别ID将是最唯一的列。因此,理想情况下,您需要按国家对表进行分区,并按生物识别ID进行桶操作。
"最初的回答"
通常,您会在较不唯一的列上进行分区,而在最唯一的列上进行桶操作。
例如,如果您考虑世界人口中的国家、个人姓名和他们的生物识别ID作为示例。正如您所猜测的那样,国家字段将是较不唯一的列,而生物识别ID将是最唯一的列。因此,理想情况下,您需要按国家对表进行分区,并按生物识别ID进行桶操作。
"最初的回答"
- SVK
1
在Hive表中使用分区是非常推荐的,原因如下:
- 将数据插入到Hive表中应该更快(因为它使用多个线程来写入分区)
- 从Hive表中查询应该效率高且延迟低。
例如:
假设输入文件(100 GB)已加载到temp-hive-table中,并包含来自不同地理位置的银行数据。
没有分区的Hive表
Insert into Hive table Select * from temp-hive-table
/hive-table-path/part-00000-1 (part size ~ hdfs block size)
/hive-table-path/part-00000-2
....
/hive-table-path/part-00000-n
这种方法的问题是 - 对于在此表上运行的任何查询,它将扫描整个数据。与使用分区和桶排序的其他方法相比,响应时间会更长。
带有分区的Hive表
Insert into Hive table partition(country) Select * from temp-hive-table
/hive-table-path/country=US/part-00000-1 (file size ~ 10 GB)
/hive-table-path/country=Canada/part-00000-2 (file size ~ 20 GB)
....
/hive-table-path/country=UK/part-00000-n (file size ~ 5 GB)
优点 - 在查询特定地理事务数据时,可以更快地访问数据。 缺点 - 通过在每个分区内拆分数据,可以进一步改善插入/查询数据。请参见下面的Bucketing选项。
带有分区和桶的Hive表
注意:使用“CLUSTERED BY(Partition_Column)into 5 buckets”创建Hive表......
Insert into Hive table partition(country) Select * from temp-hive-table
/hive-table-path/country=US/part-00000-1 (file size ~ 2 GB)
/hive-table-path/country=US/part-00000-2 (file size ~ 2 GB)
/hive-table-path/country=US/part-00000-3 (file size ~ 2 GB)
/hive-table-path/country=US/part-00000-4 (file size ~ 2 GB)
/hive-table-path/country=US/part-00000-5 (file size ~ 2 GB)
/hive-table-path/country=Canada/part-00000-1 (file size ~ 4 GB)
/hive-table-path/country=Canada/part-00000-2 (file size ~ 4 GB)
/hive-table-path/country=Canada/part-00000-3 (file size ~ 4 GB)
/hive-table-path/country=Canada/part-00000-4 (file size ~ 4 GB)
/hive-table-path/country=Canada/part-00000-5 (file size ~ 4 GB)
....
/hive-table-path/country=UK/part-00000-1 (file size ~ 1 GB)
/hive-table-path/country=UK/part-00000-2 (file size ~ 1 GB)
/hive-table-path/country=UK/part-00000-3 (file size ~ 1 GB)
/hive-table-path/country=UK/part-00000-4 (file size ~ 1 GB)
/hive-table-path/country=UK/part-00000-5 (file size ~ 1 GB)
优点 - 插入速度更快。查询速度更快。
缺点 - 分桶会创建更多的文件。在某些特定情况下,可能会出现许多小文件的问题。
希望这能帮到您!!
- Ajay Ahuja
0
我认为,
Bucketing = 在没有引起冗余数据的列较多的情况下,将数据分布。因此,我们选择具有唯一数据的列作为bucketing key。
Partitioning = 在引起冗余数据的列较少的情况下,将数据分布。因此,我们选择引起冗余的列。
如果我在这种情况下应用分区,我将选择id1或id2之一。假设我选择了id1,那么我将得到只有一个分区,其中包含1->(2->3,4,5)。这样的话,即使我将id1和id2合并在一起,性能也不会有所改善。但是,假设我将值作为键创建3个桶,这样我将得到3个均匀分布的桶,其值为3、4、5,其中有2个值为1和2。
从上面的例子可以看出,当存在大量数据时,例如上面的示例只包含一组列,并且数据较少,但是当数据很大时,分区键列变得不均匀,特别是在HDFS中,分布非常重要。因此,仅创建一个分区并反复填充它,通过嵌套另一个分区列,将导致性能问题,这就是桶化的作用所在。
谢谢,欢迎指正。
Bucketing = 在没有引起冗余数据的列较多的情况下,将数据分布。因此,我们选择具有唯一数据的列作为bucketing key。
Partitioning = 在引起冗余数据的列较少的情况下,将数据分布。因此,我们选择引起冗余的列。
Id1 id2 value
eg. 1 2 3
1 2 4
1 2 5
如果我在这种情况下应用分区,我将选择id1或id2之一。假设我选择了id1,那么我将得到只有一个分区,其中包含1->(2->3,4,5)。这样的话,即使我将id1和id2合并在一起,性能也不会有所改善。但是,假设我将值作为键创建3个桶,这样我将得到3个均匀分布的桶,其值为3、4、5,其中有2个值为1和2。
从上面的例子可以看出,当存在大量数据时,例如上面的示例只包含一组列,并且数据较少,但是当数据很大时,分区键列变得不均匀,特别是在HDFS中,分布非常重要。因此,仅创建一个分区并反复填充它,通过嵌套另一个分区列,将导致性能问题,这就是桶化的作用所在。
谢谢,欢迎指正。
- Himanshu
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接