问题: 我正在对我的DataFrame结果进行分组,使用
value_counts(normalize=True)并尝试在条形图中绘制结果。
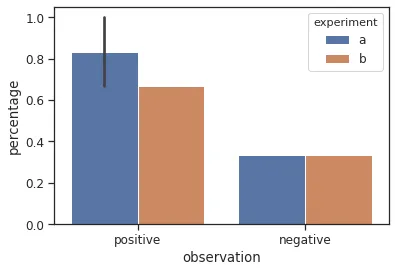
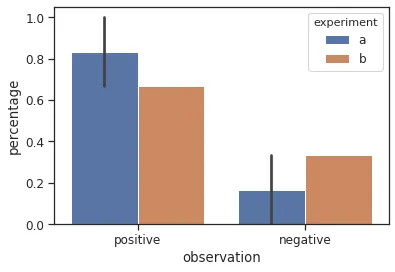
问题在于条形图应该包含频率。在某些组中,某些值不会出现。在这种情况下,相应的value_count不是0,而是不存在。对于条形图,这个0值不被考虑在内,导致得到的条形太大了。
示例: 下面是一个最简单的例子,说明了这个问题: 假设DataFrame包含实验的观察结果。当你进行这样一个实验时,一系列的观察结果会被收集起来。实验的结果是收集到的观察结果的相对频率。
df = pd.DataFrame()
df["id"] = [1]*3 + [2]*3 + [3]*3
df["experiment"] = ["a"]*6 + ["b"] * 3
df["observation"] = ["positive"]*3 + ["positive"]*2 + ["negative"]*1 + ["positive"]*2 + ["negative"]*1
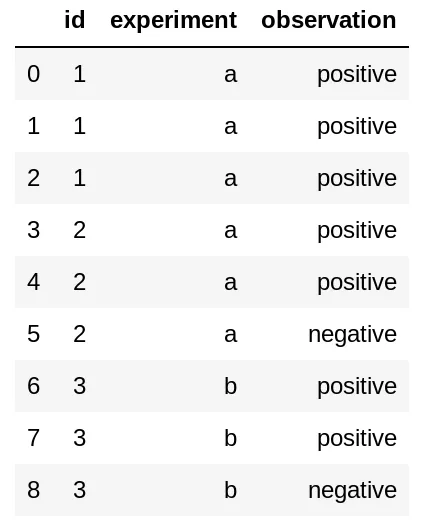
- 有两种实验类型,"a"和"b"
- 属于同一次实验评估的观测结果具有相同的id。
因此,在这里,实验a已经进行了2次,实验b只进行了1次。
我需要按id和实验分组,然后对结果取平均值。
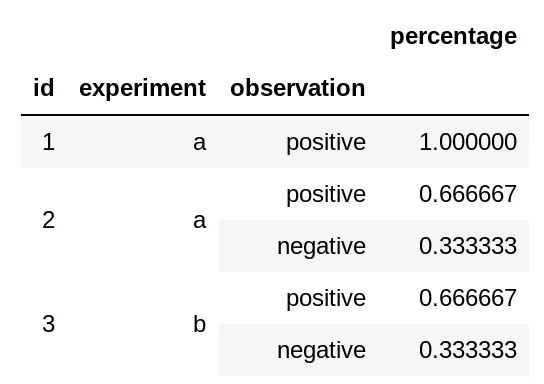
plot_frame = pd.DataFrame(df.groupby(["id", "experiment"])["observation"].value_counts(normalize=True))
plot_frame = plot_frame.rename(columns={"observation":"percentage"})
sns.barplot(data=plot_frame.reset_index(),
x="observation",
hue="experiment",
y="percentage")
plt.show()