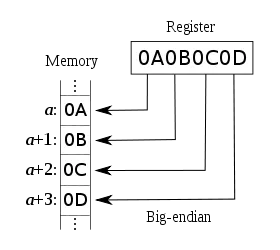
考虑到我的平台是小端字节序,我认为一个四字节整数值1应该被表示为以字节数组形式表达时的0x00, 0x00, 0x00, 0x01。因此,请有人解释一下为什么以下断言失败...
int val{1};
auto bytes = reinterpret_cast<char*>(&val);
assert(bytes[sizeof(int) - 1] == 0x01);
... 但是以下断言成功了...
assert(bytes[0] == 0x01);
在将数据强制转换为char*后,字节似乎被反转了。我的关于字节序的假设是错误的吗?编译器(clang)或语言是否抽象了字节序?到底发生了什么?