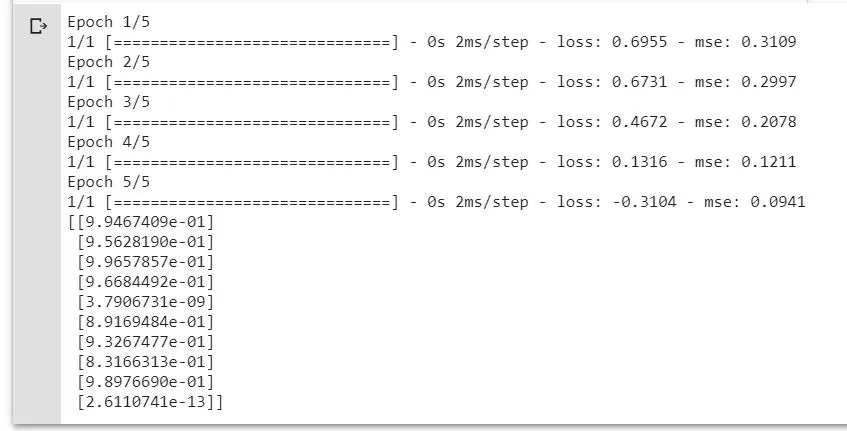
为了使结果可重复,我阅读了20多篇文章,并将尽可能多的函数添加到我的脚本中...但失败了。
在官方来源中,我看到有两种类型的种子-全局和操作性。也许,解决我的问题的关键是设置操作性种子,但我不知道在哪里应用它。
请问,您能帮助我在tensorflow(版本> 2.0)中实现可重复的结果吗?非常感谢。
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from keras.optimizers import adam
from sklearn.preprocessing import MinMaxScaler
np.random.seed(7)
import tensorflow as tf
tf.random.set_seed(7) #analogue of set_random_seed(seed_value)
import random
random.seed(7)
tf.random.uniform([1], seed=1)
tf.Graph.as_default #analogue of tf.get_default_graph().finalize()
rng = tf.random.experimental.Generator.from_seed(1234)
rng.uniform((), 5, 10, tf.int64) # draw a random scalar (0-D tensor) between 5 and 10
df = pd.read_csv("s54.csv",
delimiter = ';',
decimal=',',
dtype = object).apply(pd.to_numeric).fillna(0)
#data normalization
scaler = MinMaxScaler()
scaled_values = scaler.fit_transform(df)
df.loc[:,:] = scaled_values
X_train, X_test, y_train, y_test = train_test_split(df.iloc[:,1:],
df.iloc[:,:1],
test_size=0.2,
random_state=7,
stratify = df.iloc[:,:1])
model = Sequential()
model.add(Dense(1200, input_dim=len(X_train.columns), activation='relu'))
model.add(Dense(150, activation='relu'))
model.add(Dense(80, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
loss="binary_crossentropy"
optimizer=adam(lr=0.01)
metrics=['accuracy']
epochs = 2
batch_size = 32
verbose = 0
model.compile(loss=loss,
optimizer=optimizer,
metrics=metrics)
model.fit(X_train, y_train, epochs = epochs, batch_size=batch_size, verbose = verbose)
predictions = model.predict(X_test)
tn, fp, fn, tp = confusion_matrix(y_test, predictions>.5).ravel()