我在为Sweave编写R程序时遇到了一些问题,与#rstats Twitter小组经常指向这里,所以我想把这个问题放在SO群众中。我是一名分析师而不是程序员,所以请轻松对待我的第一个帖子。
问题如下:我正在使用R和Sweave起草一份调查报告,并希望使用
只有14%的受访者表示“X”。
我想这样写报告:
只有\Sexpr{p.mean(variable)}$\%$的受访者表示“X”。
问题在于,Sweave将
问题如下:我正在使用R和Sweave起草一份调查报告,并希望使用
\Sexpr{}在同一行中报告边际回报率。例如,而不是说:只有14%的受访者表示“X”。
我想这样写报告:
只有\Sexpr{p.mean(variable)}$\%$的受访者表示“X”。
问题在于,Sweave将
\Sexpr{}表达式的结果转换为字符字符串,这意味着R中表达式的输出和出现在我的文档中的输出是不同的。例如,上面我使用了'p.mean'函数:
p.mean<- function (x) {options(digits=1)
mmm<-weighted.mean(x, weight=weight, na.rm=T)
print(100*mmm)
}
在 R 中,输出看起来像这样:
p.mean(variable)
>14
但是当我使用\Sexpr{p.mean(variable)}时,我的文档中会得到一个未舍入的字符字符串(在这种情况下为:13.5857142857143)。我尝试在全局环境中、函数本身以及各种命令中将函数的输出限制为digits=1,但它似乎只包含R打印的内容,而不是表达式的字符转换结果,最终在LaTeX文件中打印。
as.character(p.mean(variable))
>[1] 14
>[1] "13.5857142857143"
有没有人知道我可以通过重新编程R函数或在Sweave或\Sexpr {}中设置来限制LaTeX文件中打印的数字位数?
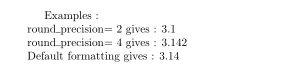
mmm<-weighted.mean(x, weight=weight, na.rm=T)
return(round(100*mmm))
} 我预先指定了权重变量,因为我试图尽量减少编程时间。由于我处理的所有数据集都将其权重变量标记为“weight”,这使得我的编写效率略微提高了一点。 - deoksu