这里有一种可能性。
这个想法是利用相似矩阵中的信息,如果两个元素相似,就把它们放在一起。如果两个物品相似,它们在其他方面也应该是相似的,例如颜色。
我从与所有其他元素共同点最多的元素[a]开始(这个选择有点随意),然后从剩余的元素中选择距离当前元素最近的元素[b]作为下一个元素。
import numpy as np
import matplotlib.pyplot as plt
def create_dummy_sim_mat(n):
sm = np.random.random((n, n))
sm = (sm + sm.T) / 2
sm[range(n), range(n)] = 1
return sm
def argsort_sim_mat(sm):
idx = [np.argmax(np.sum(sm, axis=1))]
for i in range(1, len(sm)):
sm_i = sm[idx[-1]].copy()
sm_i[idx] = -1
idx.append(np.argmax(sm_i))
return np.array(idx)
n = 10
sim_mat = create_dummy_sim_mat(n=n)
idx = argsort_sim_mat(sim_mat)
sim_mat2 = sim_mat[idx, :][:, idx]
fig, ax = plt.subplots(1, 2)
ax[0].imshow(sim_mat)
ax[1].imshow(sim_mat2)
def ticks(_ax, ti, la):
_ax.set_xticks(ti)
_ax.set_yticks(ti)
_ax.set_xticklabels(la)
_ax.set_yticklabels(la)
ticks(_ax=ax[0], ti=range(n), la=range(n))
ticks(_ax=ax[1], ti=range(n), la=idx)
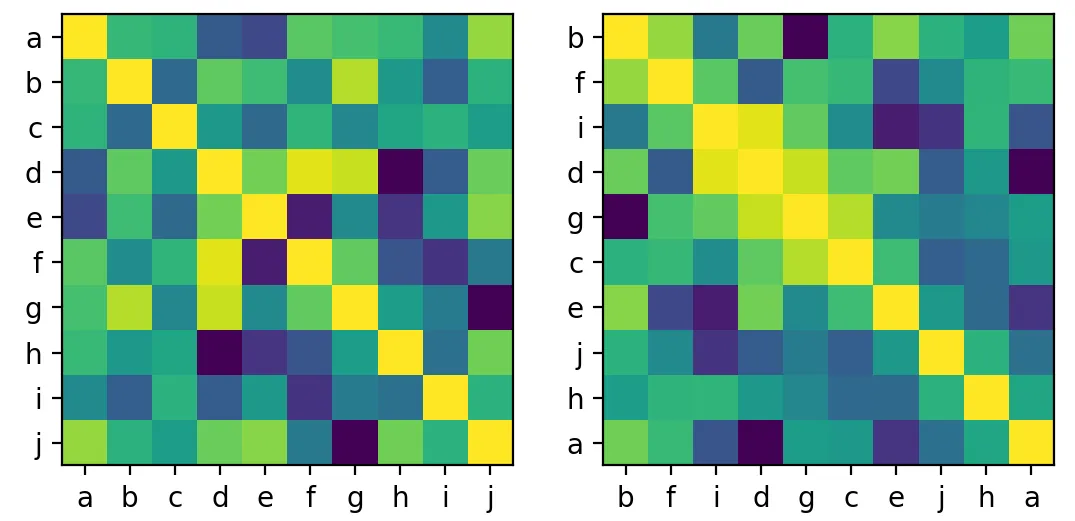
在meTchaikovsky的回答之后,我也在聚类相似度矩阵上测试了我的想法(见第一张图片),这种方法可行但不完美(见第二张图片)。
因为我使用两个元素之间的相似度来近似它们与所有其他元素的相似度,所以很明显这并不能完美地工作。因此,可以计算一个“二阶”相似度矩阵来代替使用初始相似度来排序元素,该矩阵测量相似度的相似程度(抱歉)。这个度量更好地描述了您感兴趣的内容。如果两行/列具有相似的颜色,则它们应该靠近彼此。将矩阵排序的算法与以前相同。
def add_cluster(sm, c=3):
idx_cluster = np.array_split(np.random.permutation(np.arange(len(sm))), c)
for ic in idx_cluster:
cluster_noise = np.random.uniform(0.9, 1.0, (len(ic),)*2)
sm[ic[np.newaxis, :], ic[:, np.newaxis]] = cluster_noise
def get_sim_mat2(sm):
return 1 / (np.linalg.norm(sm[:, np.newaxis] - sm[np.newaxis], axis=-1) + 1/n)
sim_mat = create_dummy_sim_mat(n=100)
add_cluster(sim_mat, c=4)
sim_mat2 = get_sim_mat2(sim_mat)
idx = argsort_sim_mat(sim_mat)
idx2 = argsort_sim_mat(sim_mat2)
sim_mat_sorted = sim_mat[idx, :][:, idx]
sim_mat_sorted2 = sim_mat[idx2, :][:, idx2]
fig, ax = plt.subplots(1, 3)
ax[0].imshow(sim_mat)
ax[1].imshow(sim_mat_sorted)
ax[2].imshow(sim_mat_sorted2)
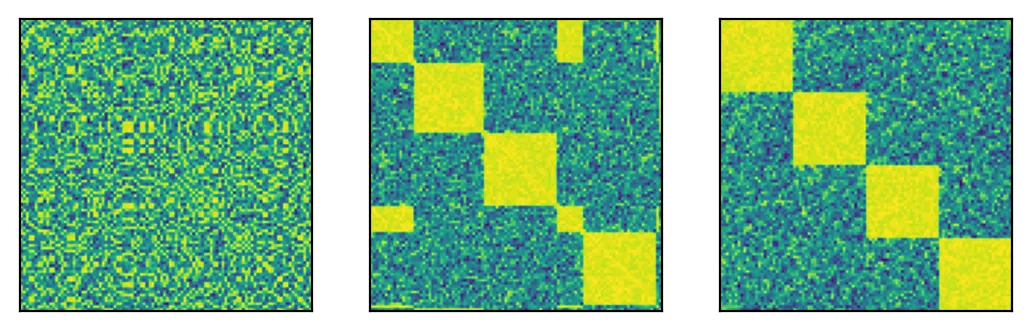
使用第二种方法得出的结果相当不错(见第三张图片),但我猜测也会存在这种方法无法奏效的情况,所以我希望能得到反馈。
编辑
我曾试图解释并用 [a] 和 [b] 将代码与思路联系起来,但显然我做得不好,所以这里有一个更详细的解释。
你有 n 个元素和一个 n x n 的相似度矩阵 sm,其中每个单元格 (i, j) 描述了元素 i 与元素 j 之间的相似程度。目标是按照一定顺序排列行 / 列,以便可以看到相似度矩阵中存在的模式。我的想法非常简单。
你从一个空列表开始,并逐个添加元素。下一个元素的标准是与当前元素的相似性。如果上一步添加了元素 i,则选择元素 argmax(sm[i, :]) 作为下一个元素,忽略已添加到列表中的元素。通过将那些元素的值设置为 -1 来忽略它们。
你可以使用函数 ticks 来重新排序标签:
labels = np.array(labels)
ticks(_ax=ax[0], ti=range(n), la=labels[idx])
def argsort_sim_mat(sm)这段代码的含义吗?另外,我如何重新排序标签呢? - lynx