根据图论,您需要从边的数组中创建一个图,然后找到该图的连通组件。对于我来说,纯numpy方案似乎太难了,但您仍然可以使用以C语言编写的igraph将其提升至C级别(与纯Python的networkx不同)。您需要先安装python-igraph。
微不足道的情况下,igraph.Graph.clusters()方法返回一个特殊实例的igraph.clustering.VertexClustering类,它可以转换为list:
import igraph
arr = np.array([[0, 4], [0, 7], [1, 2], [1, 9], [2, 1], [2, 8], [3, 10],
[3, 11], [4, 0], [4, 5], [5, 4], [5, 6], [6, 5], [6, 7], [7, 0], [7, 6]])
g = ig.Graph()
g.add_vertices(12)
g.add_edges(arr)
i = g.clusters()
print(list(i))
igraph 也支持绘制这些连通组件,就像在networkx中一样,但您可能需要从非官方二进制文件下载pycairo并安装它,以解锁igraph.plot选项:
pal = ig.drawing.colors.ClusterColoringPalette(len(i))
color = pal.get_many(i.membership)
ig.plot(g, bbox = (200, 100), vertex_label=g.vs.indices,
vertex_color = color, vertex_size = 12, vertex_label_size = 8)
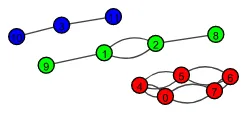
通用情况
注意,如果使用初始数组而不是平凡数组,则igraph会抛出InternalError。这是因为在添加边之前必须声明每个顶点,并且所有顶点都不允许有缺失的编号(实际上是允许的,但重新索引是静默完成的,旧名称可以使用“name”属性访问)。可以编写自定义函数来从重新标记的边创建图以解决此问题:
def create_from_edges(edgelist):
g = ig.Graph()
u, inv = np.unique(edgelist, return_inverse=True)
e = inv.reshape(edgelist.shape)
g.add_vertices(u)
g.add_edges(e)
return g
arr = np.array([[0, 4], [0, 7], [1, 2], [1, 13], [2, 1], [2, 9], [3, 14],
[3, 16], [4, 0], [4, 5], [5, 4], [5, 6], [6, 5], [6, 7], [7, 0], [7, 6]])
g = create_from_edges(arr)
i = g.clusters()
print(list(i))
新标签被用于输出(因此使其不正确),但仍然可以像这样访问旧标签:
print('new_names:', g.vs.indices)
print('old_names:', g.vs['name'])
>>> new_names: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
>>> old_names: [0, 1, 2, 3, 4, 5, 6, 7, 9, 13, 14, 16]
它们可以用于预览原始图形(vertex_label 现在不同):
pal = ig.drawing.colors.ClusterColoringPalette(len(i))
color = pal.get_many(i.membership)
ig.plot(g, bbox = (200, 100), vertex_label=g.vs['name'],
vertex_color = color, vertex_size = 12, vertex_label_size = 8)
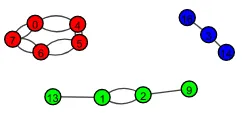
最后,您需要使用旧的顶点名称来修复输出。可以像这样完成:
output = list(i)
old_names = np.array(g.vs['name'])
fixed_output = [old_names[n].tolist() for n in output]