有一个"将外键放到父级"的方法,即每个记录指向其父级。
这对于阅读操作来说很困难,但非常易于维护。
然后还有一个"目录结构键"方法:
0001.0000.0000.0000 main branch 1
0001.0001.0000.0000 child of main branch one
etc
这种写法很容易阅读,但难以维护。
还有哪些方式以及它们的优缺点?
有一个"将外键放到父级"的方法,即每个记录指向其父级。
这对于阅读操作来说很困难,但非常易于维护。
然后还有一个"目录结构键"方法:
0001.0000.0000.0000 main branch 1
0001.0001.0000.0000 child of main branch one
etc
这种写法很容易阅读,但难以维护。
还有哪些方式以及它们的优缺点?
Retrieving a whole tree and finding all parents is easy and cheap
Inserting and updating is relatively cheap
No recursion needed in SQL, so it's faster than the Naive Approach
Can handle non-hierarchical relationships as well
Cons:
Requires an additional table to store the closure information
More complex to implement compared to other solutions
易于实现
查找所有父节点成本低廉
插入成本低廉
检索整个树的成本低廉
缺点:
需要额外的表格
与其他方法相比占用大量空间
移动子树成本高昂
我更喜欢最后两种方法之一,具体取决于数据变化的频率。
这是一种使用非递归函数(通常是单行SQL语句)从数据库中检索树的方法,代价是更新稍微复杂一些。
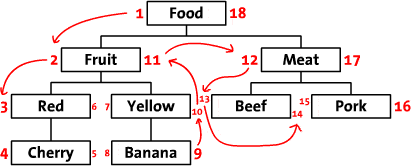
请参阅Sitepoint文章“在数据库中存储分层数据”的第2节,以获取更多详细信息。
我认为使用关系型数据库构建树形结构并不难。
然而,面向对象的数据库对于这个目的会更加有效。
使用面向对象的数据库:
parent has a set of child1
child1 has a set of child2
child2 has a set of child3
...
...
parent
id
name
child1
parent_fk
id
name
child2
parent_fk
id
name
..
基本上,在构建树形结构时,您将不得不连接所有这些表,或者您可以对它们进行迭代。
foreach(parent in parents){
foreach(child1 in parent.child1s)
foreach(child2 in child1.child2s)
...