I have the following code:
import numpy as np
import pandas as pd
obs = pd.DataFrame({
'storm': [1, 1, 1, 1, 0, 0, 0, 0],
'lightning': [1, 1, 0, 0, 1, 1, 0, 0],
'thunder': [1, 0, 1, 0, 1, 0, 1, 0],
'p': [0.20, 0.05, 0.04, 0.36, 0.04, 0.01, 0.03, 0.27]
})
g1=obs.groupby(['lightning','thunder']).agg({'p':'sum'})
g2=obs.groupby(['lightning','thunder','storm']).agg({'p':'sum'})
这提供了如下信息:
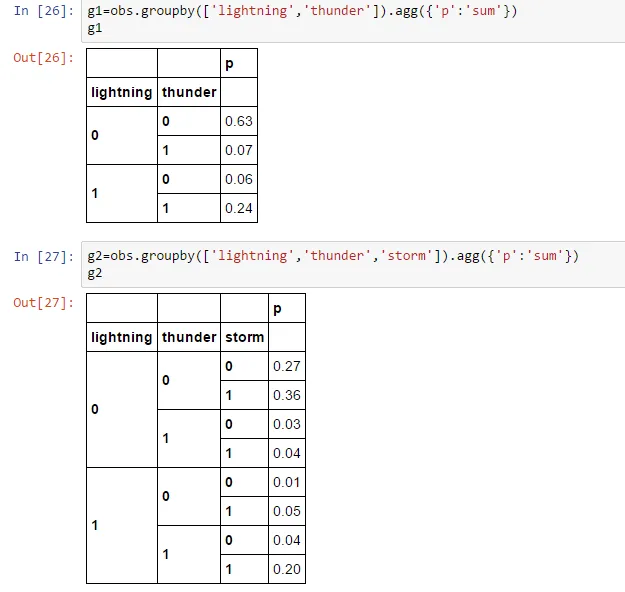
现在如何通过较少详细的分组划分更详细的分组(计算百分比)?
我阅读了这篇Pandas percentage of total with groupby,但无法推导出如何为我的情况进行重写。
