我有一个包含游戏数据的数据框。在这个游戏中,两名玩家会玩90分钟的比赛。但是由于各种原因,比赛可能持续时间超过90分钟。我想要找到在90分钟后玩家1获胜的比赛。因此,我想要比较比赛的结束得分:
- 持续时间超过90分钟,
- 玩家1获胜
与时间<90分钟的先前得分相比。
例如,在游戏1中,在第95分钟之前,比分还保持平局,但是第95分钟时,选手1获胜。总的来说,如果在90分钟之前两个选手打成平局,或者在90分钟后选手1处于落后状态,但最终情况是选手1获胜,我该如何过滤这种情况?
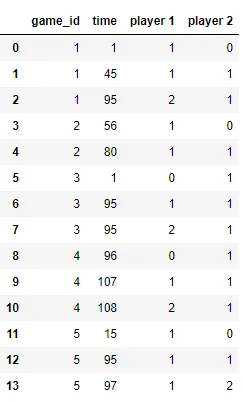
(来源:imggmi.com)
{kind=link}
# Games dataframe
games = pd.DataFrame({'game_id': {0: 1,1: 1,2: 1,3: 2,4: 2,5: 3,6: 3,7:
3,8: 4,9: 4,10: 4,11: 5,12: 5,13: 5},
'time': {0: 1,1: 45,2: 95,3: 56,4: 80,5: 1,6: 95,7:
95,8: 96,9: 107,10: 108,11: 15,12: 95,13: 97},
'player 1': {0: 1,1: 1,2: 2,3: 1,4: 1,5: 0,6: 1,7: 2,8:
0,9: 1,10: 2,11: 1,12: 1,13: 1},
'player 2': {0: 0,1: 1,2: 1,3: 0,4: 1,5: 1,6: 1,7: 1,8:
1,9: 1,10: 1,11: 0,12: 1,13: 2}})
# Find the rows with the ending scores of games
a = games.drop_duplicates(["game_id"],keep='last')
#Find games that player 1 wins and time>90
b = games[((games["player 1"] - games["player 2"]) >0) (games["time"]>90)]
例如,在游戏1中,在第95分钟之前,比分还保持平局,但是第95分钟时,选手1获胜。总的来说,如果在90分钟之前两个选手打成平局,或者在90分钟后选手1处于落后状态,但最终情况是选手1获胜,我该如何过滤这种情况?