我正在尝试完成Analytics Vidhya的贷款预测机器学习实践问题。在使用随机森林分类器时,出现以下错误:
TypeError:float() argument must be a string or a number, not 'pandas._libs.interval.Interval'
代码:
train['Loan_Status']=np.where(train['Loan_Status']=='Y', 1,0)
train_test_data=[train,test]
#Gender Feature
for dataset in train_test_data:
dataset["Gender"]=dataset["Gender"].fillna('Male')
for dataset in train_test_data:
dataset["Gender"]=dataset["Gender"].map({ "Female" : 1 , "Male" : 0}).astype(int)
#Married Feature
for dataset in train_test_data:
dataset['Married']=dataset['Married'].fillna('Yes')
for dataset in train_test_data:
dataset['Married']=dataset['Married'].map({"Yes" : 1 , "No" : 0}).astype(int)
#Education Feature
for dataset in train_test_data:
dataset['Education']=dataset['Education'].map({'Graduate' : 1 , 'Not Graduate' : 0}).astype(int)
#Combine Applicant income and coapplicant income
for dataset in train_test_data:
dataset['Income']=dataset['ApplicantIncome']+dataset['CoapplicantIncome']
train['IncomeBand']= pd.cut(train['Income'] , 4)
print(train[['IncomeBand' , 'Loan_Status']].groupby(['IncomeBand'] , as_index=False).mean())
for dataset in train_test_data:
dataset.loc[dataset['Income'] <= 21331.5, 'Income'] =0
dataset.loc[(dataset['Income'] > 21331.5) & (dataset['Income'] <= 41221.0), 'Income'] =1
dataset.loc[(dataset['Income'] > 41221.0) & (dataset['Income'] <= 61110.5), 'Income'] =2
dataset.loc[dataset['Income'] > 61110.5, 'Income'] =3
dataset['Income']=dataset['Income'].astype(int)
# Loan Amount Feature
fillin=train.LoanAmount.median()
for dataset in train_test_data:
dataset['LoanAmount']=dataset['LoanAmount'].fillna(fillin)
train['LoanAmountBand']=pd.cut(train['LoanAmount'] , 4)
print(train[['LoanAmountBand' , 'Loan_Status']].groupby(['LoanAmountBand'] , as_index=False).mean())
for dataset in train_test_data:
dataset.loc[dataset['LoanAmount'] <= 181.75, 'LoanAmount'] =0
dataset.loc[(dataset['LoanAmount'] >181.75) & (dataset['LoanAmount'] <= 354.5), 'LoanAmount'] =1
dataset.loc[(dataset['LoanAmount'] > 354.5) & (dataset['LoanAmount'] <= 527.25), 'LoanAmount'] =2
dataset.loc[dataset['LoanAmount'] > 527.25, 'LoanAmount'] =3
dataset['LoanAmount']=dataset['LoanAmount'].astype(int)
#Loan Amount Term Feature
for dataset in train_test_data:
dataset['Loan_Amount_Term']=dataset['Loan_Amount_Term'].fillna(360.0)
Loan_Amount_Term_mapping={360.0 : 1 , 180.0 : 2 , 480.0 : 3 , 300.0 : 4 , 84.0 : 5 , 240.0 : 6, 120.0 :7 , 36.0:8 , 60.0 : 9, 12.0 :10}
for dataset in train_test_data:
dataset['Loan_Amount_Term']=dataset['Loan_Amount_Term'].map(Loan_Amount_Term_mapping)
# Credit History Feature
for dataset in train_test_data:
dataset['Credit_History']=dataset['Credit_History'].fillna(2)
# Property Area Feature
for dataset in train_test_data:
dataset['Property_Area']=dataset['Property_Area'].map({'Semiurban' : 0 , 'Urban' : 1 , 'Rural' : 2}).astype(int)
# Feature Selection
features_drop=['Self_Employed' , 'ApplicantIncome' , 'CoapplicantIncome', 'Dependents']
train=train.drop(features_drop, axis=1)
test=test.drop(features_drop, axis=1)
train.drop(['Loan_ID' , 'IncomeBand' , 'LoanAmountBand'] , axis=1)
X_train=train.drop('Loan_Status' , axis=1)
y_train=train['Loan_Status']
X_test=test.drop('Loan_ID' , axis=1).copy()
X_train.shape , y_train.shape , X_test.shape
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
y_pred_random_forest = clf.predict(X_test)
acc_random_forest = round(clf.score(X_train, y_train) * 100, 2)
print (acc_random_forest)
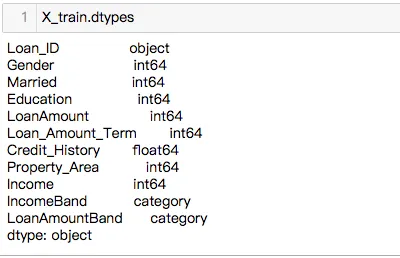
我不知道浮点数错误是从哪里来的。如果有任何建议,将不胜感激。
X.train.dtypes并在此处添加结果。如果您最小化代码以说明问题,那也会很有帮助,参见 [mcve]。 - Shaido