我有一个包含许多行的数据帧。有时候值只出现一次,对我的目的来说没有什么用处。
如何删除所有列2和3的值不超过5次的行?
df输入:
Col1 Col2 Col3 Col4
1 apple tomato banana
1 apple potato banana
1 apple tomato banana
1 apple tomato banana
1 apple tomato banana
1 apple tomato banana
1 grape tomato banana
1 pear tomato banana
1 lemon tomato banana
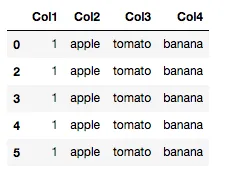
输出
Col1 Col2 Col3 Col4
1 apple tomato banana
1 apple tomato banana
1 apple tomato banana
1 apple tomato banana
1 apple tomato banana
apple也可能出现在Col3中吗? - cs95Col3的第一个值是“potato”,那么期望的输出应该是什么? - Tai